简数导航:简数控制台 采集入门教程 数据导出发送 采集翻译 采集场景示例
详情提取器
详情提取器最大优点是可视化采集和自动生成提取规则,不用去看页面源代码,鼠标点选简单快捷完成采集规则配置;
可视化自定义选择采集内容,根据需求添加或删除,如标题,作者,正文,时间,标签等等;
主要功能使用说明:
1.可视化配置规则
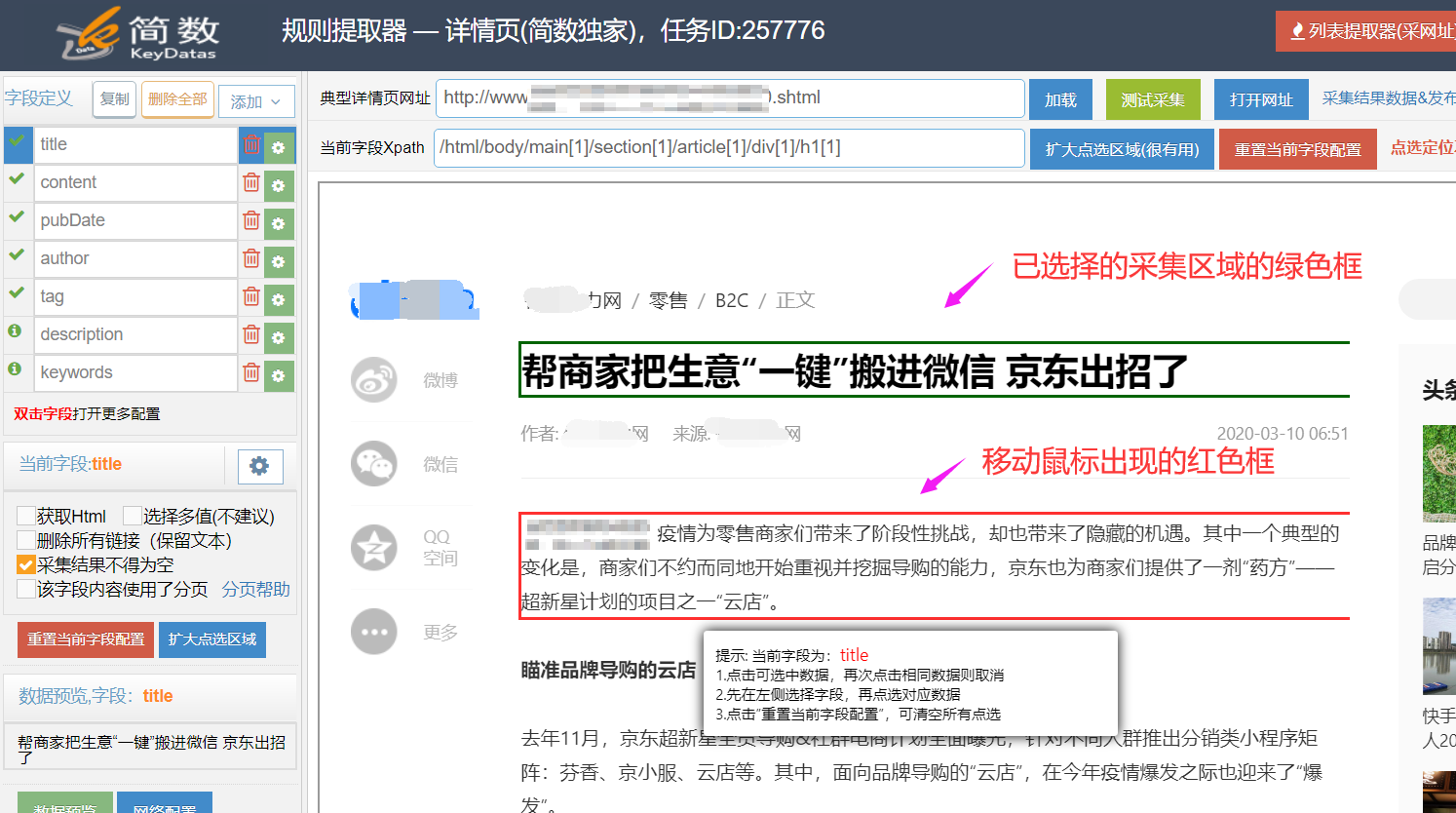
I、可视化区域
详情提取器右侧显示页面区域为可点选自动生成采集规则的可视化区域,在区域中移动鼠标,会出现红色方框,当框住需要采集的内容时,点击鼠标左键(确认的操作),就会变成绿色的方框,表示该内容已被选中采集;
如果要取消选中的内容,再次用鼠标左键点击绿色方框即可;
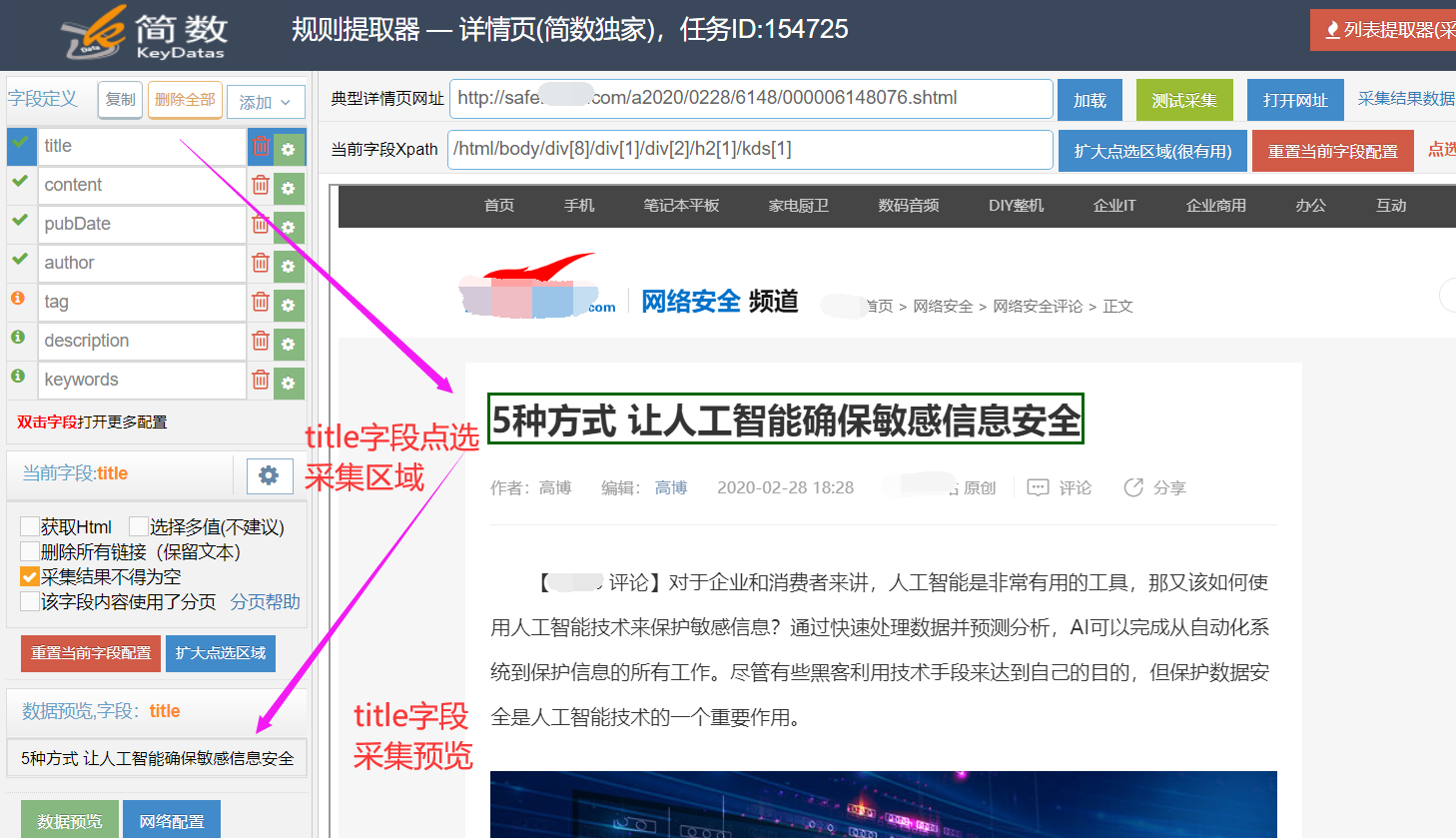
II、典型详情页网址
【典型详情页网址】是对应显示在可视化区域页面的网址,可输入新的网址或点击输入栏出现下拉列表(来源列表提取器提取的链接),选择别的文章页网址加载;
典型详情页网址右侧按钮功能:
【加载】:重新加载当然典型网址对应的页面;
【打开网址】:在浏览器新窗口中打开当前典型网址(即目标网站原始页面)。
【测试采集】:根据已配置的采集规则,采集当前页面的内容(只采集一条数据,点击后自动弹出新窗口显示采集结果数据,注意浏览器的拦截弹窗功能),可起如下作用:
1) 检查采集规则的正确性;
2) 检查采集规则的通用性,要配合典型详情页网址下拉列表,选择其他网址,再测试采集;

III、当前字段Xpath
当前字段Xpath是定位采集范围的路径,在可视化区域点选采集内容时系统自动生成的,用户一般可以忽略不管的;
当前字段Xpath右侧按钮功能:
【扩大点选区域】:如果采集范围比较难定位,可以先选择小的范围,然后点击【扩大点选区域】按钮,慢慢扩大选择范围(可点击多次),当获得需要的采集范围时,就可点击右上方的【保存】按钮,详细教程可看提取器技巧:点选采集内容时,定位不到区块问题解决方法
【重置当前字段配置】:清空当前字段已选择的采集范围(即清空当前字段xpath路径)和配置的数据处理;
如果只需取消已选择的采集范围,直接删除当前字段Xpath输入栏的内容即可;
注意:当前字段xpath路径也可以手动填写(一般用点选系统自动生成即可),需要懂一点HTMl标签基础,详细教程Xpath简单用法;
2.字段设置
I、字段基本定义
详情提取器页面左侧上方一列title、content、pubDate等参数称之为字段,可以理解为表格表头各列的名称,各行的数据对应不同的内容。
字段前面有个状态提醒,
- 绿色 ✔ 号表示已选择采集区域;
- 橙色 ✔ 号表示该字段设置了内容过滤排除功能;
- 绿色 i 号表示系统设置的通用字段(一般是description和keywords字段,基本所有网站都通用);
- 橙色 i 号表示未选择采集区域(但可能是固定或随机值);
每个字段都是相互独立的,可以设置对应的采集范围和数据处理,切换字段只需点击对应字段名称,其左右两边底色变成蓝色,下方的当前字段显示对应的字段名称。
智能向导创建采集任务,为了简化操作会默认设置一些常用字段。一般代表什么意思呢?
title(标题),content(内容),pubDate(日期),author(作者),category(分类)
tag(标签),description(描述),keywords(关键字),

II、字段自定义
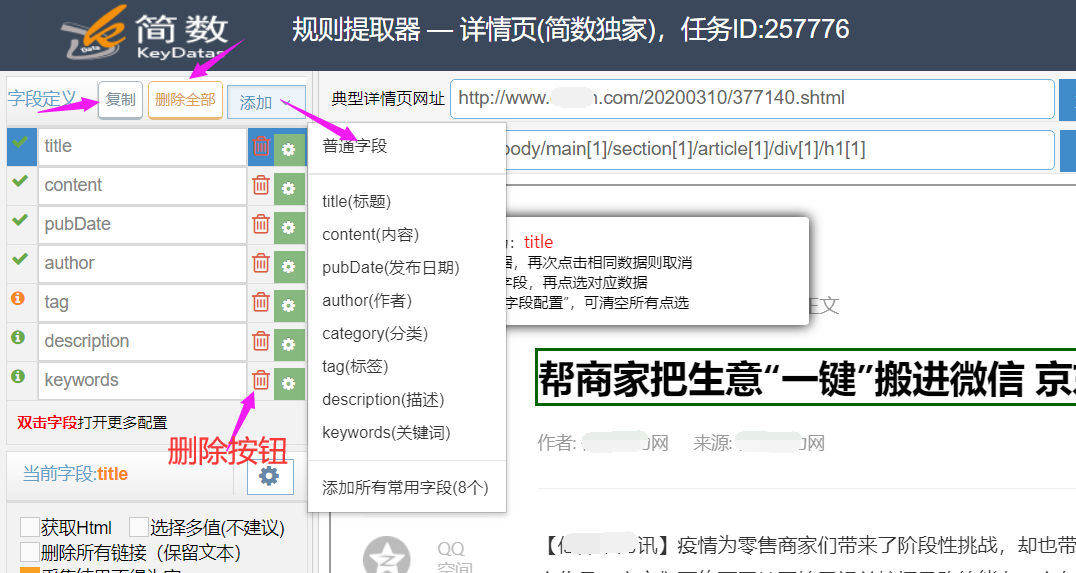
字段支持自定义,可添加、修改、删除或重命名:
字段删除:点击字段名右侧的红色垃圾桶,即为删除该字段,一次性删除全部字段在字段列上方;
字段添加:字段列上方的添加按钮,可以添加普通字段(无任何设置的空字段),系统常用字段单个或全部(title,author,pubDate,content,tag,description,keywords,category);
字段复制:复制按钮在字段列上方,复制当前选择字段的所有设置(包括xpath路径和数据处理);
字段重命名:左键单击对应字段名,进入修改命名状态,名称支持中文,但不要包括特殊字符或空格,更不要输入URL!(建议不要修改系统默认常用字段名称,有些功能只对默认名称的字段生效)
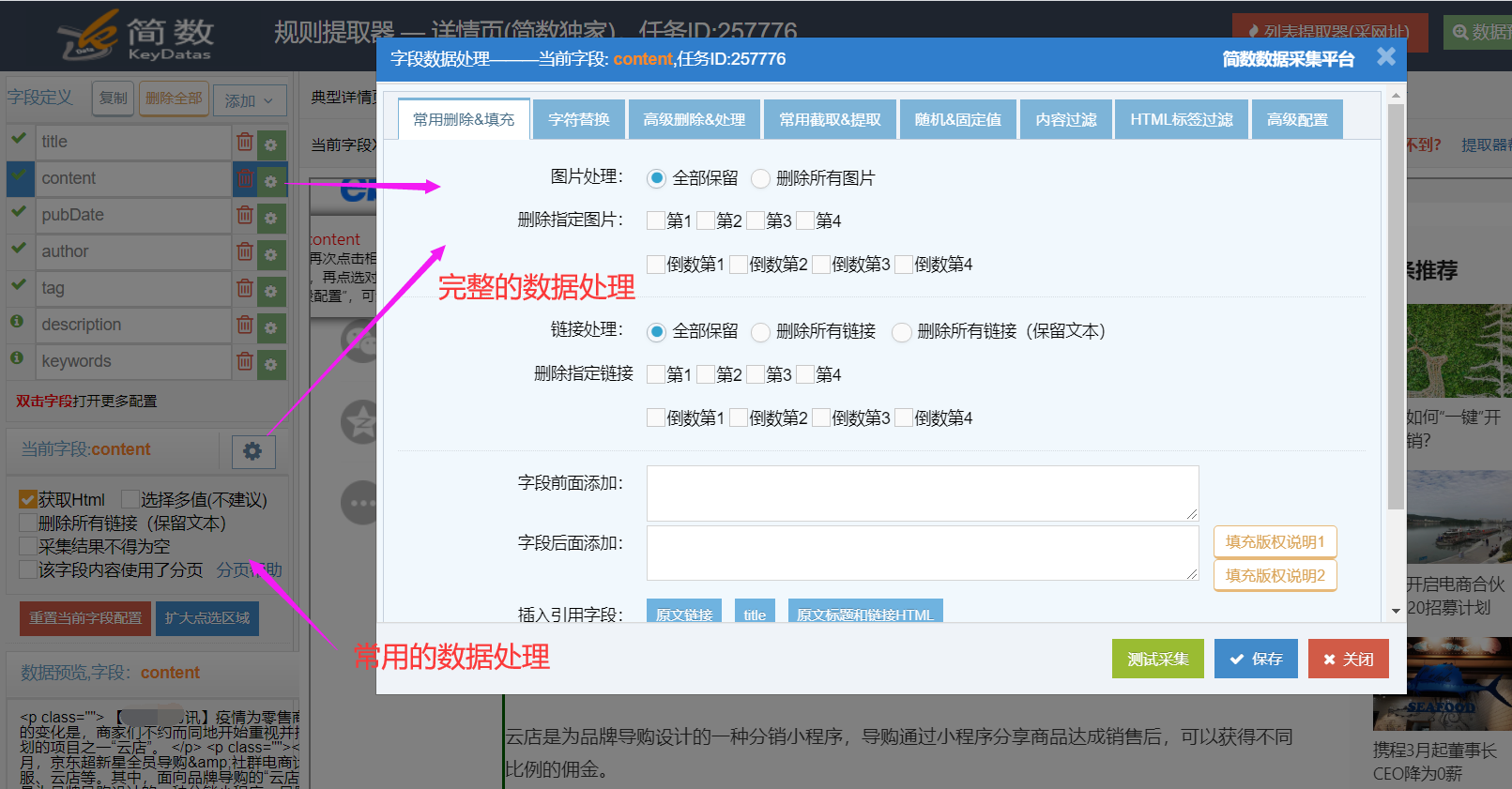
III、字段数据处理
字段可设置数据处理:填充(例如版权说明)、提取、随机或固定值等等。
常用的数据处理在详情提取器页面左侧数据预览上方,勾上即使用该数据处理功能;
完整的数据处理工具,点击对应字段右侧绿色齿轮按钮或者当前字段旁的齿轮按钮。