简数导航:简数首页 简数控制台 采集入门教程 数据导出发送 采集翻译
常用截取&提取
主要功能是使用正则表达式提取或替换匹配的内容。
主要功能使用方法:
1. 常用截取&提取表达式

简数文章采集提供常见的提取和截取正则表达式,不懂正则语法也可轻松使用,只需点击下对应的按钮;
注意:如果没匹配到要保留的内容则该字段会变为空内容,所以需要时才设置;
例子:假设日期和其他信息混在一起,无法通过选择区域分开,这时可使用日期提取功能,记得最后保存:

2. 自定义正则表达式
可自定义填写正则表达式提取或替换需要的内容,如果没匹配到内容则该字段为空内容;
将匹配的内容:填写正则表达式,匹配原值中符合条件的所有内容;
替换为:如果不填,会提取匹配的内容; 如果填写了,匹配的内容会被填写的值替换,原值其他内容保持不变;
正则捕获组:使用正则捕获语法提取内容(就是匹配括号中的内容会被提取),该处只能提取不能替换; 注意:正则捕获只会匹配符合条件的第一个内容,而不是所有都匹配;
多组值分隔符:如果正则捕获组有多个,该值会作为分隔符,默认为空;
注意:如果【字符替换】、【将匹配的内容】和【正则捕获组】同时设置了,【将匹配的内容】先执行,然后【正则捕获组】再执行,最后【字符替换】执行;

3. 前后截取功能
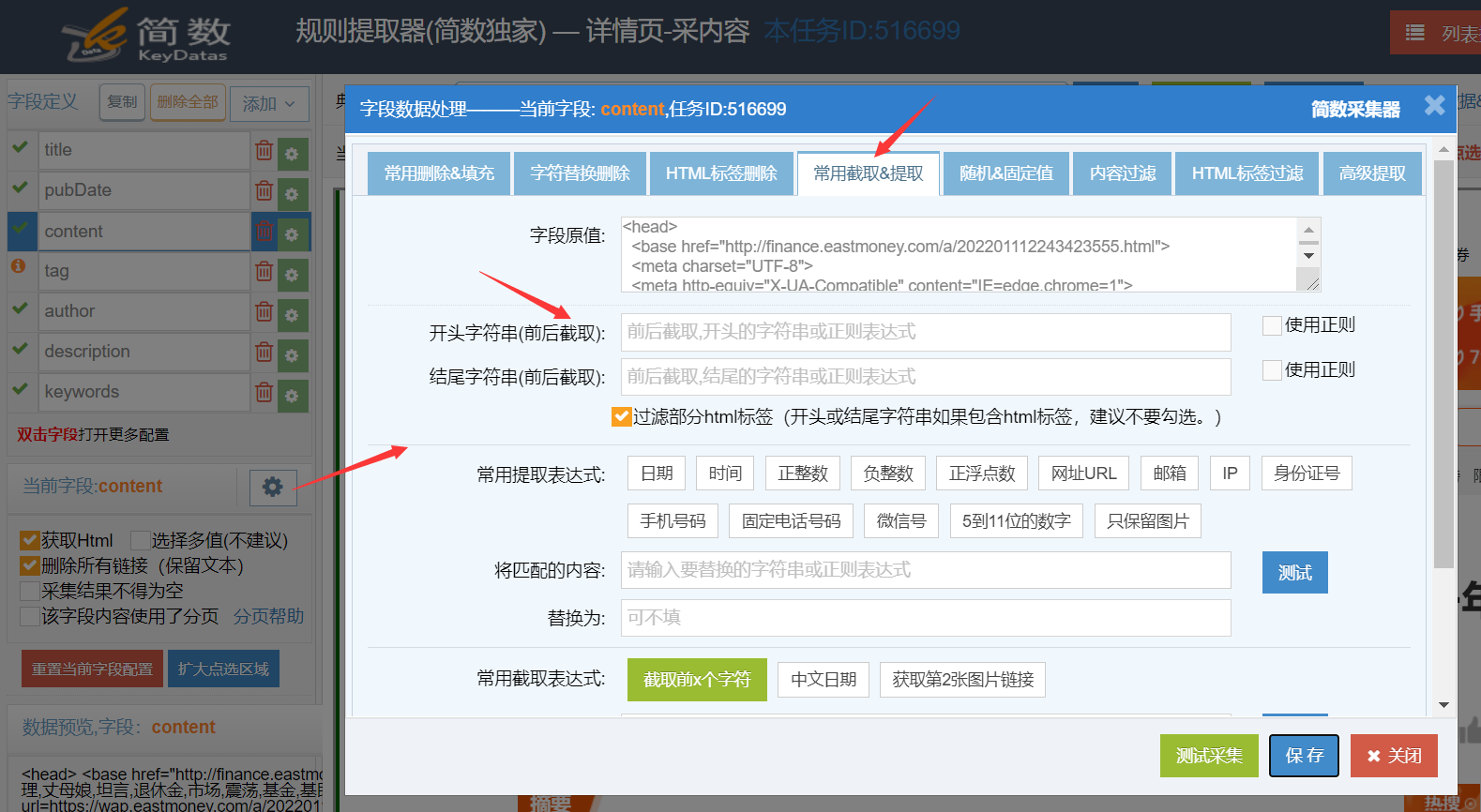
可截取开头字符串和结尾字符串之间的内容作为采集内容,一般建议使用鼠标点选自动生成采集规则方式更为方便。
开头字符串(前后截取):可填写文本,Html代码,正则表达式(需勾上后面的使用正则);
结尾字符串(前后截取):可填写文本,Html代码,正则表达式(需勾上后面的使用正则),可为空不填写(即一直截取到所选采集区域结尾);
过滤部分html标签:默认即可,如果截取内容为空,或者开头结尾字符串中包含html代码(例如含有class,id等属性),去掉不勾选【过滤部分html标签】,才可以成功截取到内容的;
- 不勾上使用【过滤部分html标签】功能,页面的html代码会完整保留下来,包括html标签属性,脚本标签,注释等;
- 如果无法截取到内容,请检查以下设置:
- I. 字段数据处理的【HTML标签过滤】页面的获取html为勾上使用;
- II. 字段数据处理的【HTML标签过滤】页面的过滤部分html标签为不勾上;
- III. 当前字段xpath值改为
/html
备注:如果截取后有多余的内容,可以使用字符替换正则替换删除,例如删除标签属性(class=".*?"和id=".*?"),脚本标签(<script[\s\S]+?</script>),注释(<\!--[\s\S]+?-->)等;