简数导航:简数首页 简数控制台 采集入门教程 数据导出发送 采集翻译
字段数据处理配置(采集前,在“详情提取器”中配置)
数据处理主要功能:
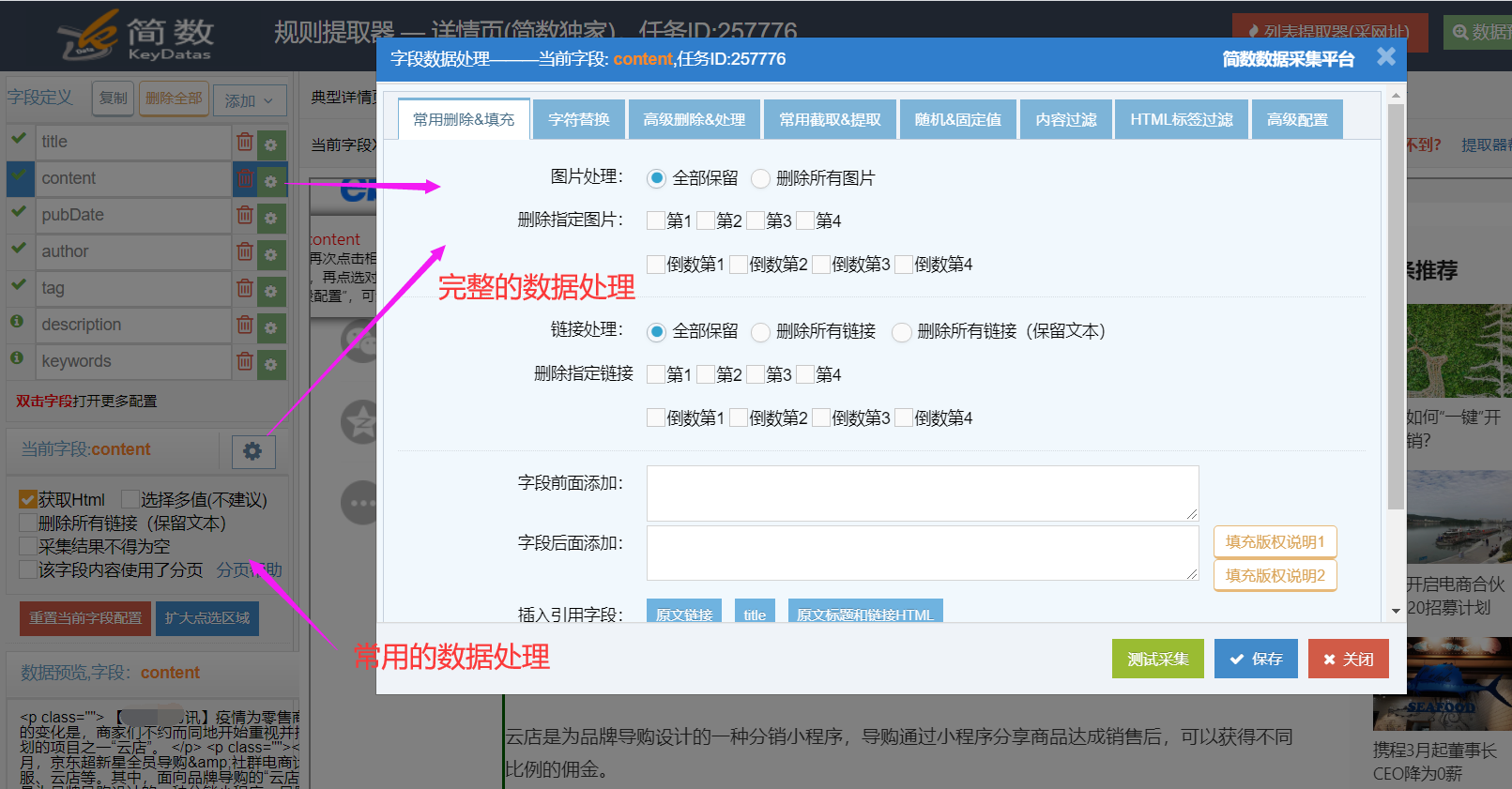
1. 图片&链接删除
可快速删除该字段内容中全部或指定位置的图片和链接。
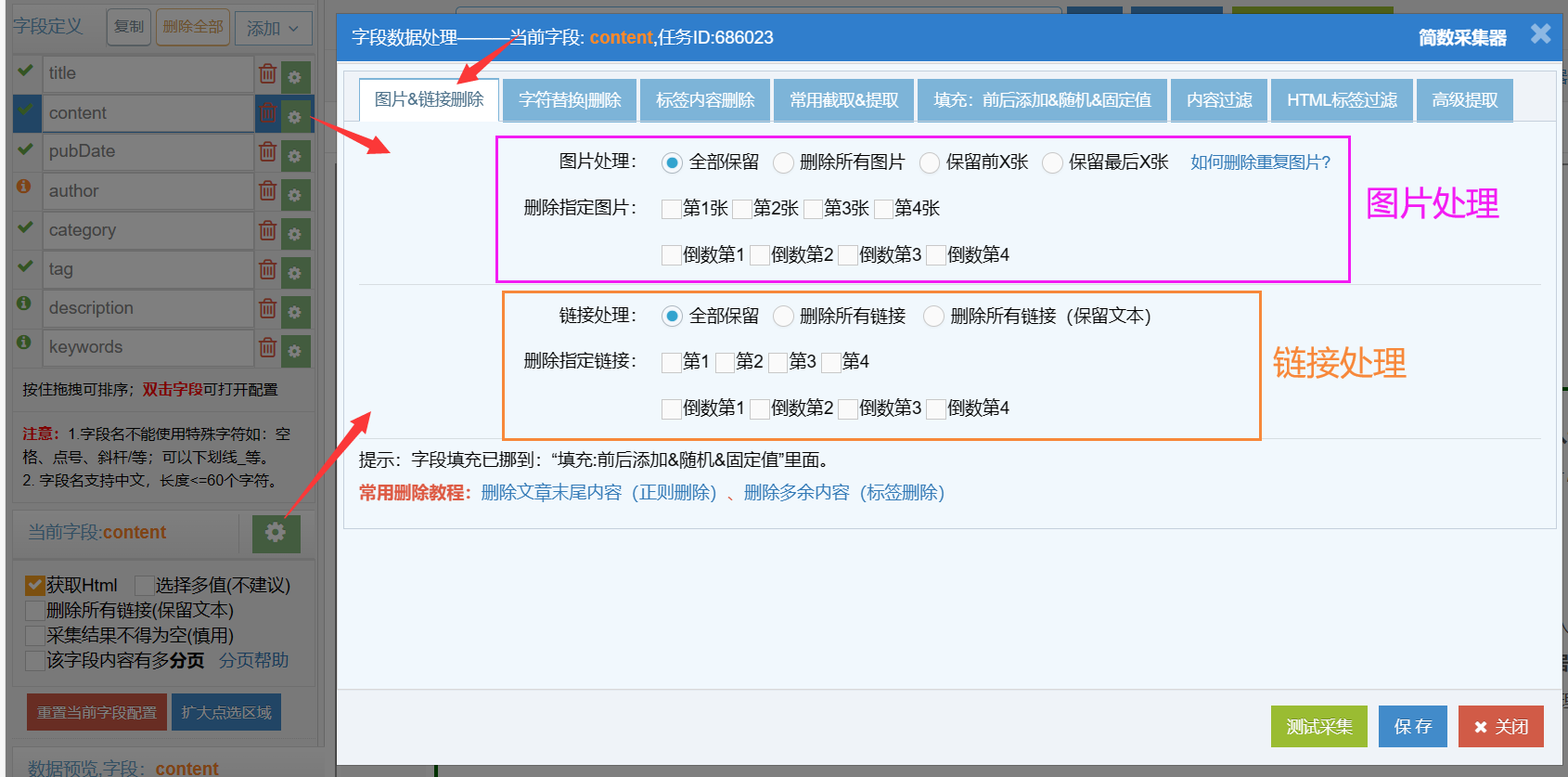
注意:【图片&链接快速删除】只对设置了获取html的字段有效,一般在content字段中使用。
1)图片删除
支持快速删除该字段内容中全部或指定位置的图片,还支持只保留前面或后面几张图片。

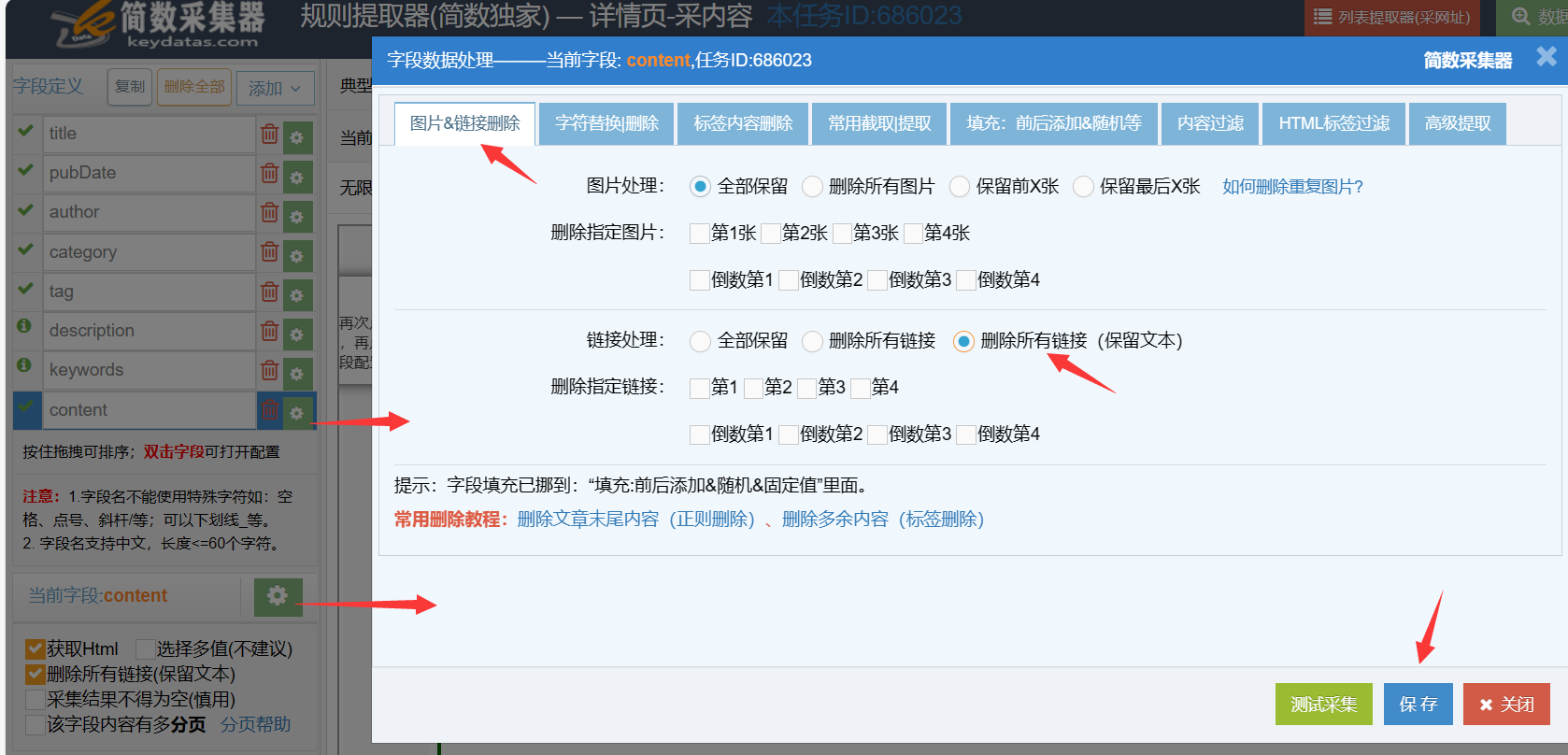
2)链接删除
支持快速删除该字段内容中全部或指定位置的链接(<a>标签),可选择保留链接中的文本内容,只删除链接。
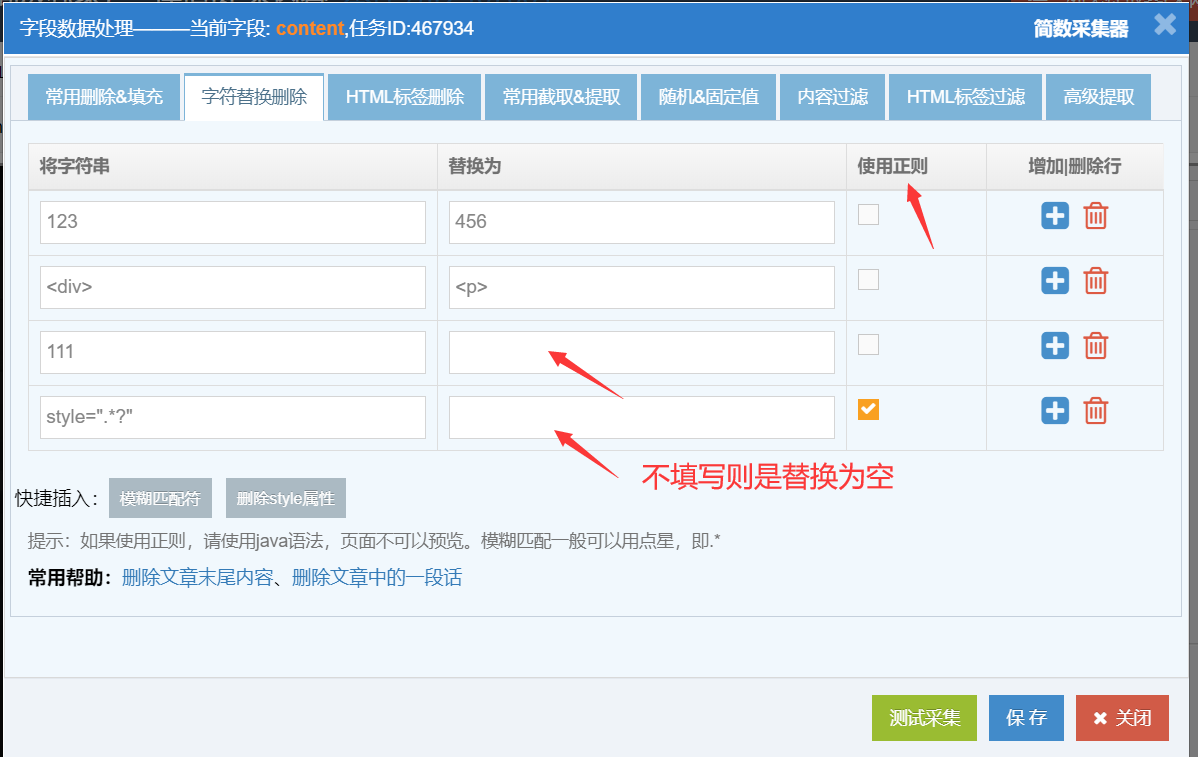
2. 字符替换
字符替换的几种使用方法:
1)简单字符替换
在【将字符串】列填写要替换掉的值(文本或html标签都支持),在【替换为】列填写要新插入的值;
可自定义添加或删除替换规则,多个替换规则执行顺序是从上到下替换的;
删除字符,是在【替换为】列不填写值,即替换为空;
2)字符正则替换(模糊匹配)
在【将字符串】列填写带有正则语法的表达式,然后勾上使用正则功能即可,注意保存;
正则基础语法可看正则表达式常用语法;

3)常用的字符正则替换
采集的内容中出现一些不需要的额外信息时,如果有共同点就可以使用字符正则替换来删除,下面介绍几种常见的情况。
正则基础语法可看正则表达式常用语法。
I、删除文章末尾内容
采集的文章末尾有额外信息(内容不固定),但是共同点都是某个词固定为开头的,类似(有些有冒号,有些没有,看实际情况的):
- 推荐文章:
- 相关推荐:
- 编辑推荐;
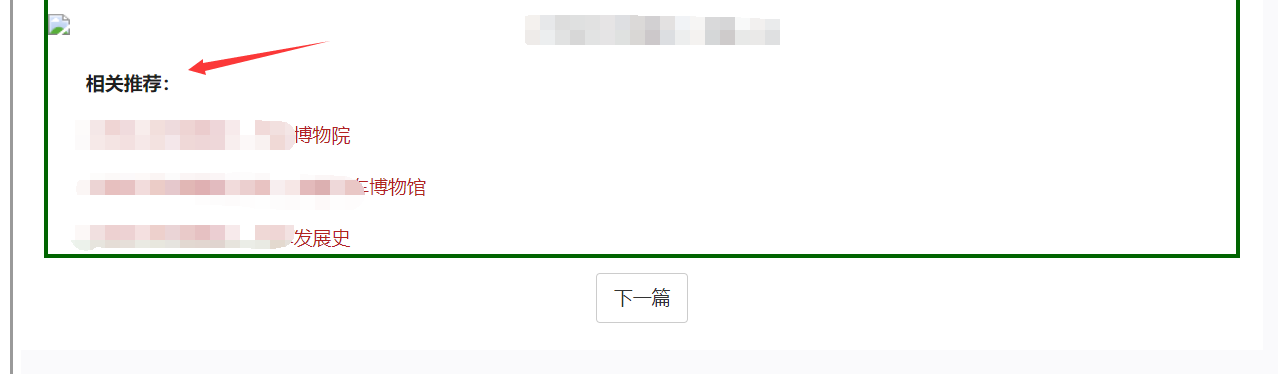
设置相对应的字符正则替换,格式为固定词[\s\S]+,然后再测试采集查看效果的;
推荐文章:[\s\S]+相关推荐:[\s\S]+编辑推荐[\s\S]+

II、删除文章中的一段话
采集的文章中有不要的一段话内容,没有换行且部分内容不固定,但是共同点都是某个词固定为开头的,类似:
- 简数站推荐:(不固定的商品广告推荐语)
- 本站为大家提供(不固定的商品广告推荐语)
设置相对应的字符正则替换,格式为固定词.+,然后再测试采集查看效果的;
简数站推荐:.+本站为大家提供.+

III、删除文章中的样式
如果想清除采集文章中的字体大小,颜色,段落间接等,可以删除style属性。
在字符替换处,点击【将字符串处】的输入框,再点击下方的【删除style属性】按钮,然后勾上使用正则,最后保存即可。

3. HTML标签删除
用于删除HTML标签及其包含内容,可以指定位置和数量,支持保留文本;
常用于删除正文第一个段落(删除前面1个p标签),还有删除最后一个段落(删除最后1个p标签)。
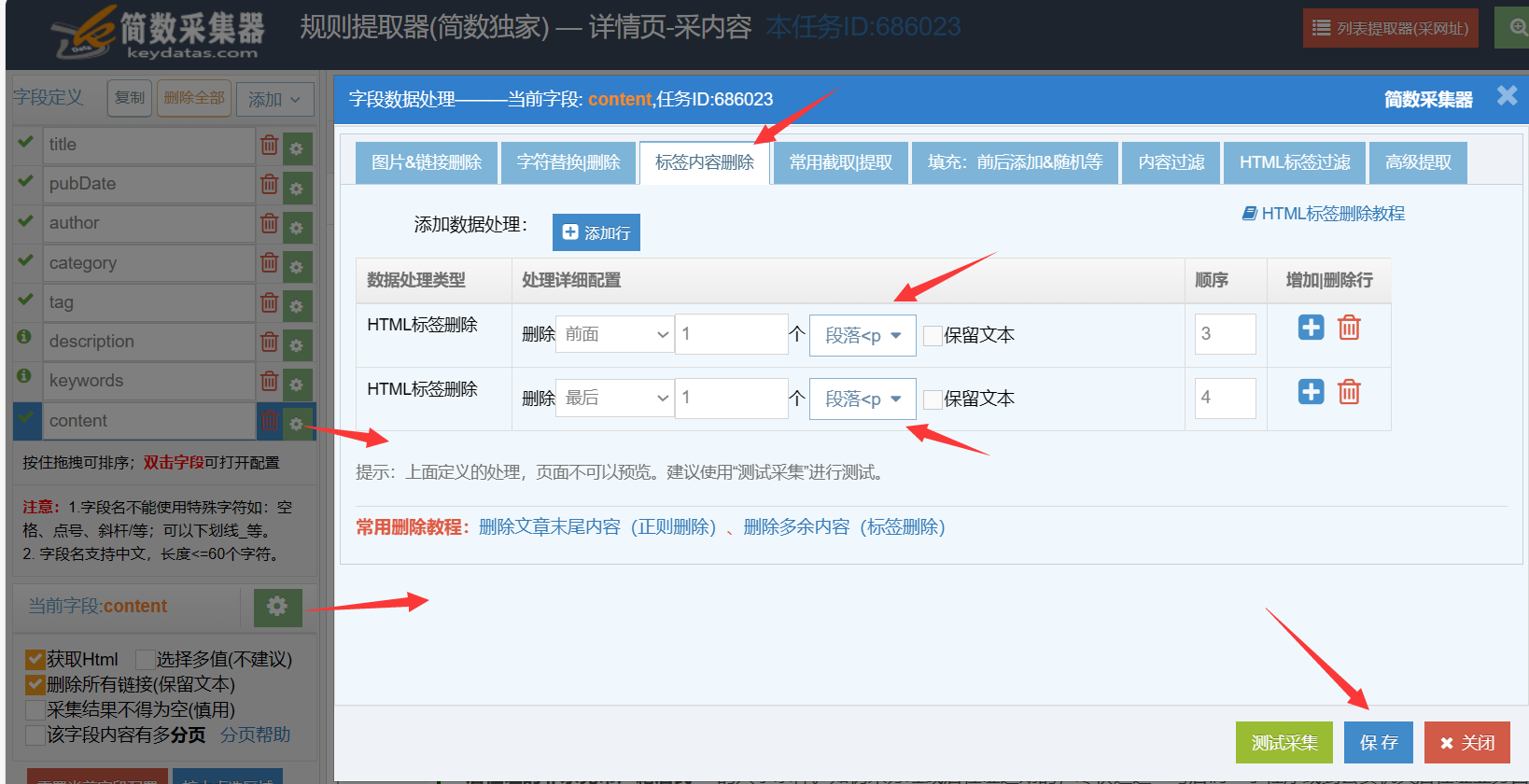
完整使用说明:
1)HTML标签删除
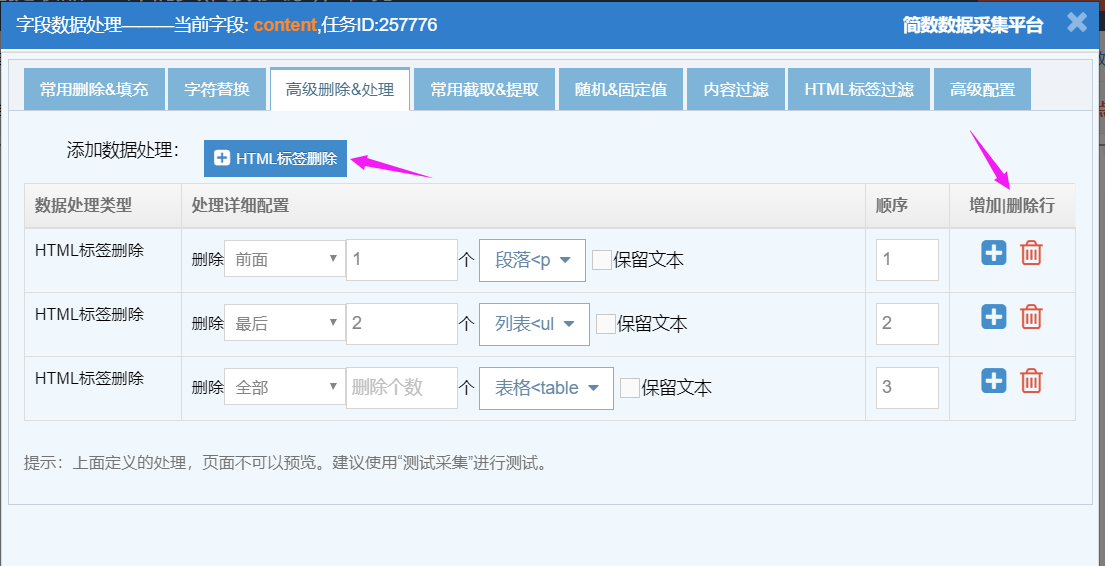
HTML标签删除可设置以下属性:
指定删除位置:前面,最后,第几个,倒数第几个,全部;
删除数量:填写数字,如果指定位置选择全部,此处则不用填写;
删除的标签名称:系统提供一些常见的标签,点击选择,支持搜索;
保留文本:勾上则保留标签中的文本,默认不保留;
顺序:支持添加多个标签删除规则,系统自动创建对应的数字顺序,可以自行调整;
注意:HTML标签删除功能生效的前提是,该字段设置了获取Html;
2)删除多余内容
有些正文前面或者后面会添加一些宣传,广告等多余内容, 如果在选择采集区域时无法将多余信息和正文分开时,且每篇文章都有一样的多余内容,就可以尝试用删除HTML标签来解决。
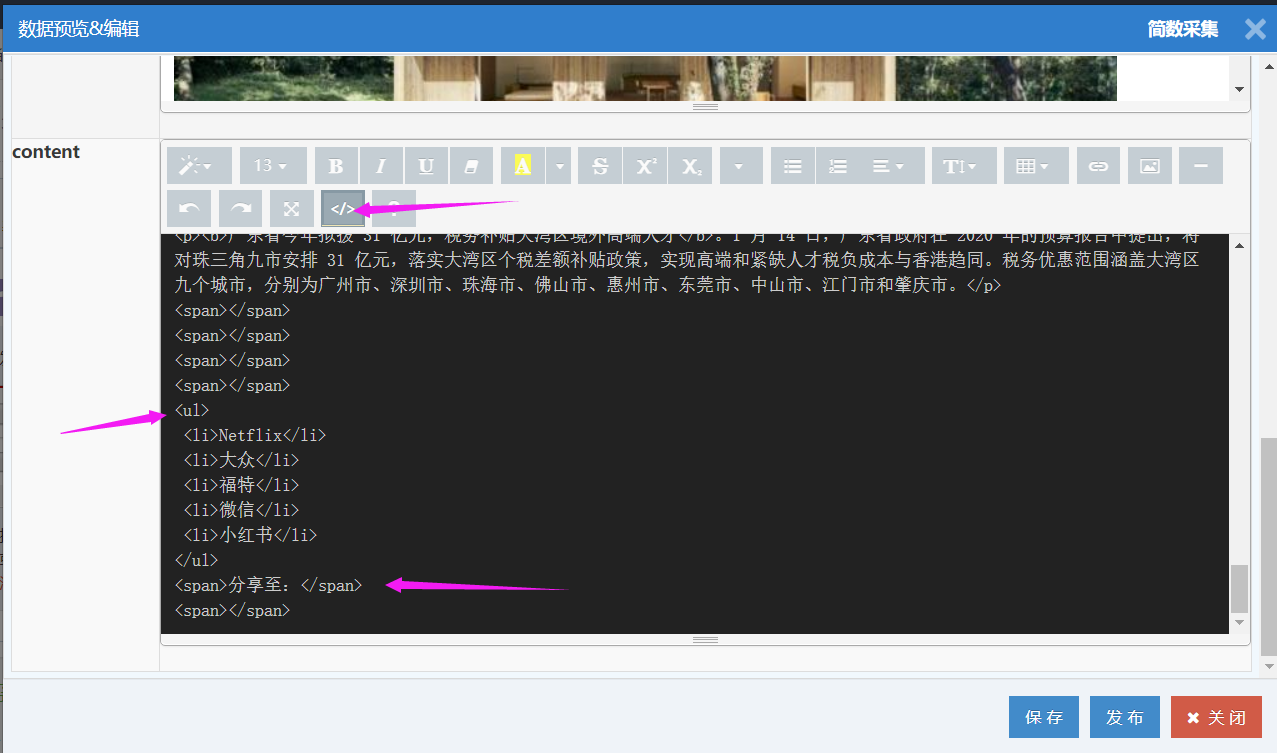
I、获取多余内容标签
测试采集,查看数据预览的代码模式;
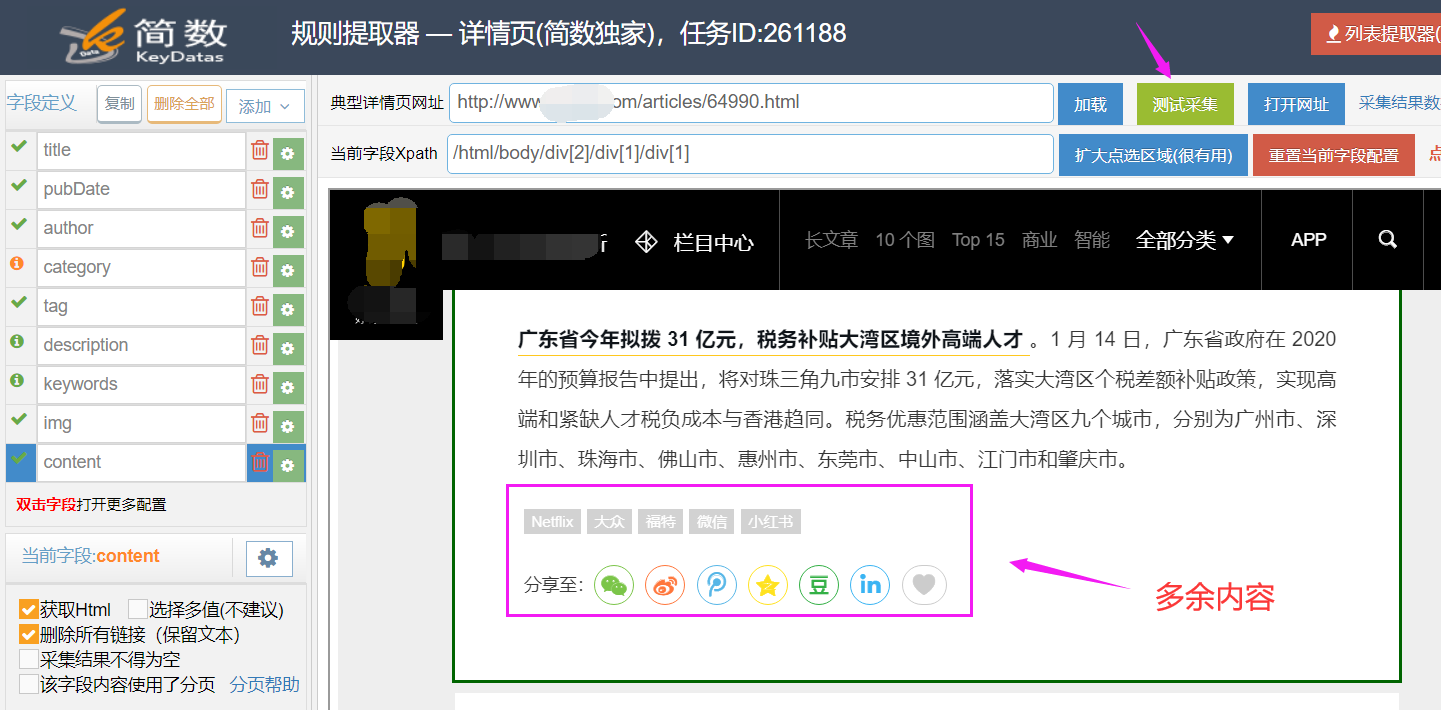
II、删除HTML标签设置
从预览代码可以看出,只要删除最后两个span标签和最后一个ul标签(ul标签包含多个li标签,所以删除ul更好)即可;
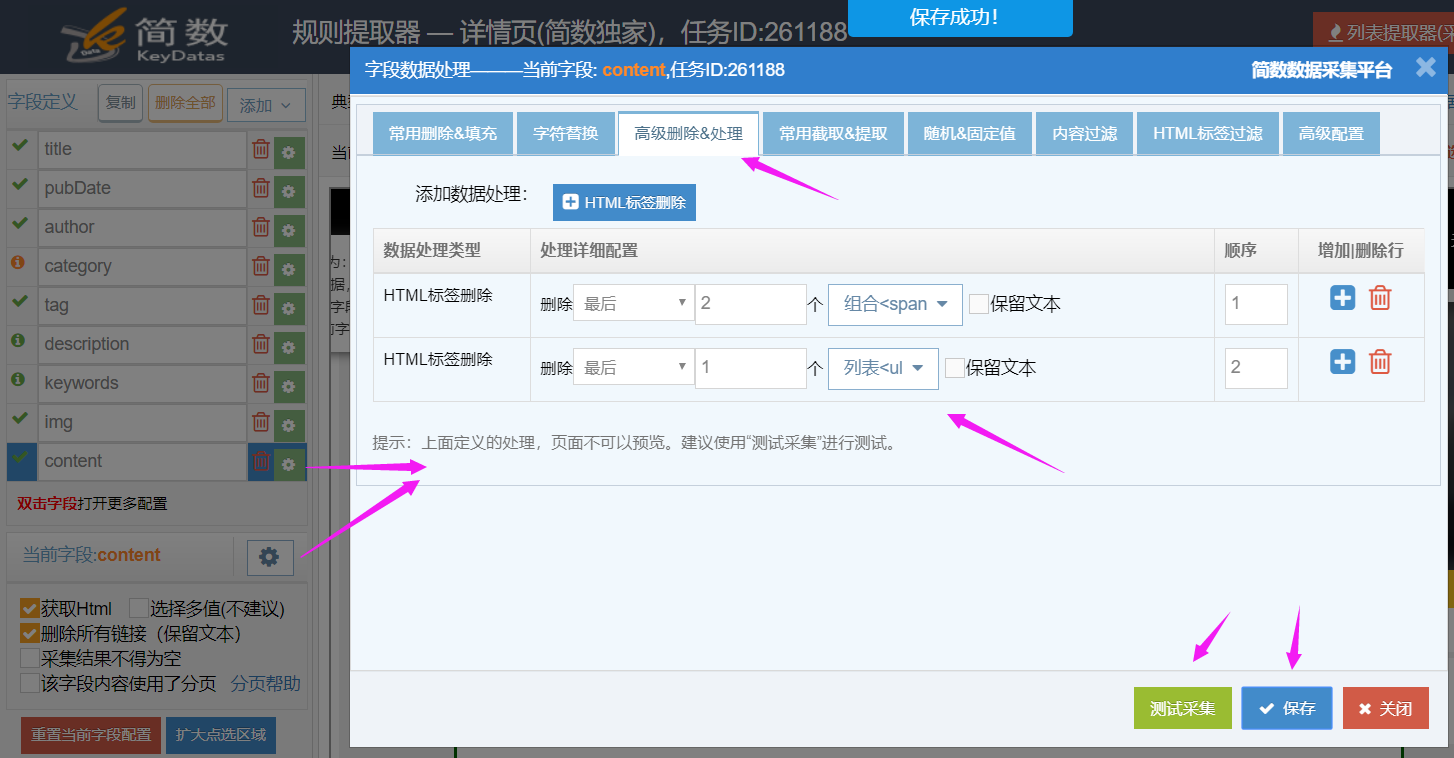
III、采集结果
重新测试采集,查看采集结果;

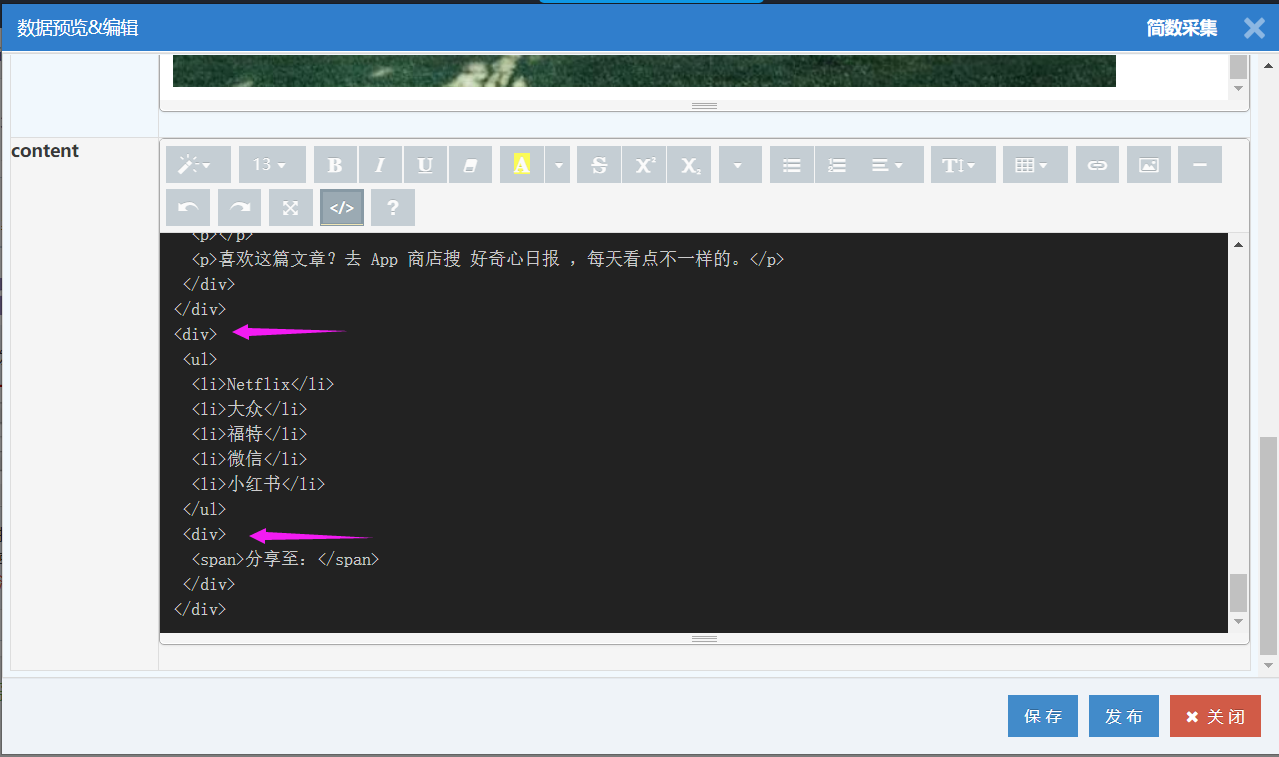
IV、无标签文本
如果只出现文本,没有对应包裹的标签,可能是系统默认过滤部分不常用的标签导致,可以先设置保留对应标签,再进行删除;
较常见的是div标签,先设置保留div标签,再删除对应div标签;


4. 常用截取&提取
主要功能是使用正则表达式提取或替换匹配的内容。
详细使用方法:
1)常用截取&提取表达式

简数文章采集提供常见的提取和截取正则表达式,不懂正则语法也可轻松使用,只需点击下对应的按钮;
注意:如果没匹配到要保留的内容则该字段会变为空内容,所以需要时才设置;
例子:假设日期和其他信息混在一起,无法通过选择区域分开,这时可使用日期提取功能,记得最后保存:

2)自定义正则表达式
可自定义填写正则表达式提取或替换需要的内容,如果没匹配到内容则该字段为空内容;
将匹配的内容:填写正则表达式,匹配原值中符合条件的所有内容;
替换为:如果不填,会提取匹配的内容; 如果填写了,匹配的内容会被填写的值替换,原值其他内容保持不变;
正则捕获组:使用正则捕获语法提取内容(就是匹配括号中的内容会被提取),该处只能提取不能替换; 注意:正则捕获只会匹配符合条件的第一个内容,而不是所有都匹配;
多组值分隔符:如果正则捕获组有多个,该值会作为分隔符,默认为空;
注意:如果【字符替换】、【将匹配的内容】和【正则捕获组】同时设置了,【将匹配的内容】先执行,然后【正则捕获组】再执行,最后【字符替换】执行;

3)前后截取功能
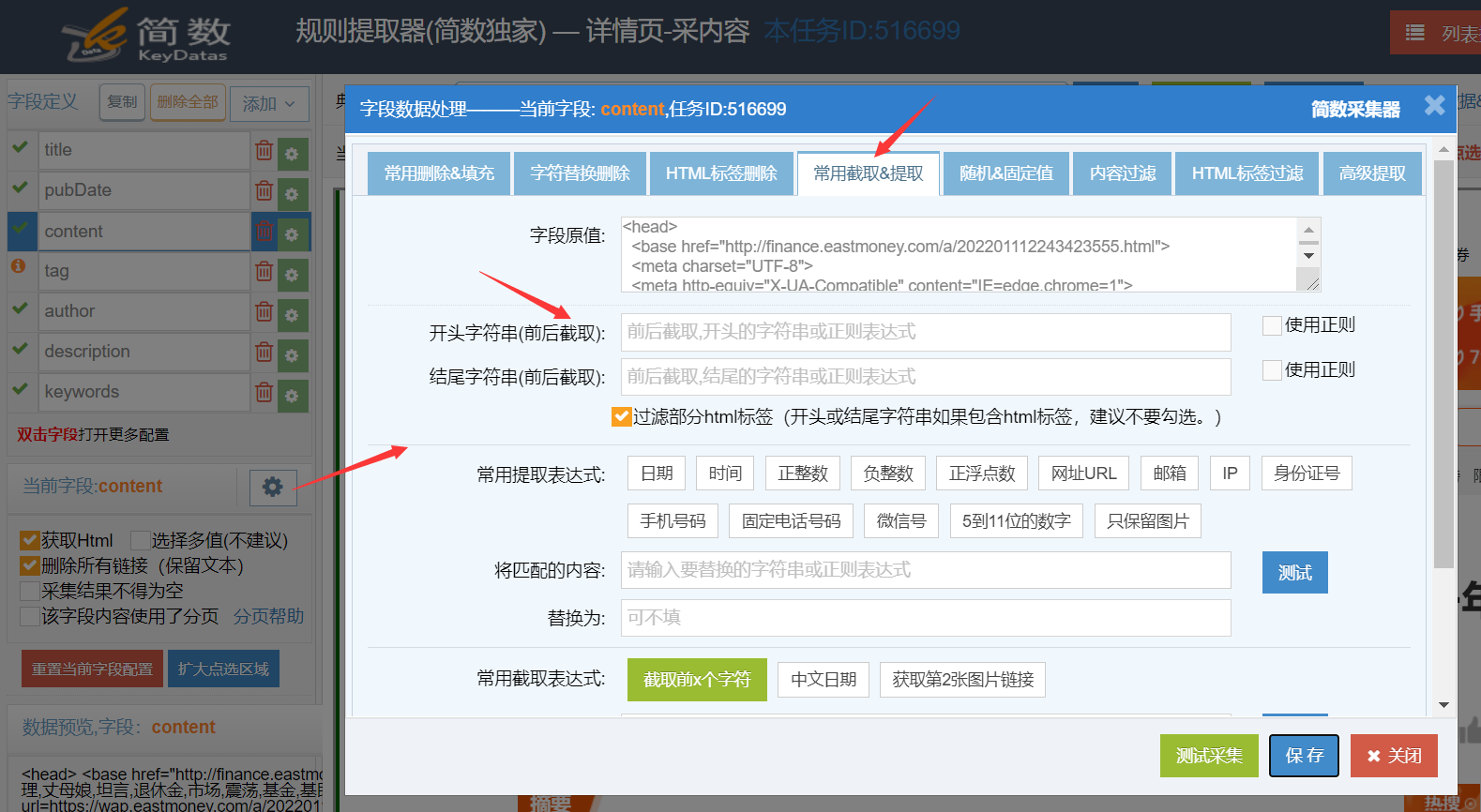
可截取开头字符串和结尾字符串之间的内容作为采集内容,一般建议使用鼠标点选自动生成采集规则方式更为方便。
开头字符串(前后截取):可填写文本,Html代码,正则表达式(需勾上后面的使用正则);
结尾字符串(前后截取):可填写文本,Html代码,正则表达式(需勾上后面的使用正则),可为空不填写(即一直截取到所选采集区域结尾);
过滤部分html标签:默认即可,如果截取内容为空,或者开头结尾字符串中包含html代码(例如含有class,id等属性),去掉不勾选【过滤部分html标签】,才可以成功截取到内容的;
- 不勾上使用【过滤部分html标签】功能,页面的html代码会完整保留下来,包括html标签属性,脚本标签,注释等;
- 如果无法截取到内容,请检查以下设置:
- I. 字段数据处理的【HTML标签过滤】页面的获取html为勾上使用;
- II. 字段数据处理的【HTML标签过滤】页面的过滤部分html标签为不勾上;
- III. 当前字段xpath值改为
/html
备注:如果截取后有多余的内容,可以使用字符替换正则替换删除,例如删除标签属性(class=".*?"和id=".*?"),脚本标签(<script[\s\S]+?</script>),注释(<\!--[\s\S]+?-->)等;
5. 字段前后填充内容&随机值、固定值、默认值
字段前后可填充内容,也可引用同条数据的其他字段内容,还支持将字段设置为随机值、固定值和默认值。
使用说明:
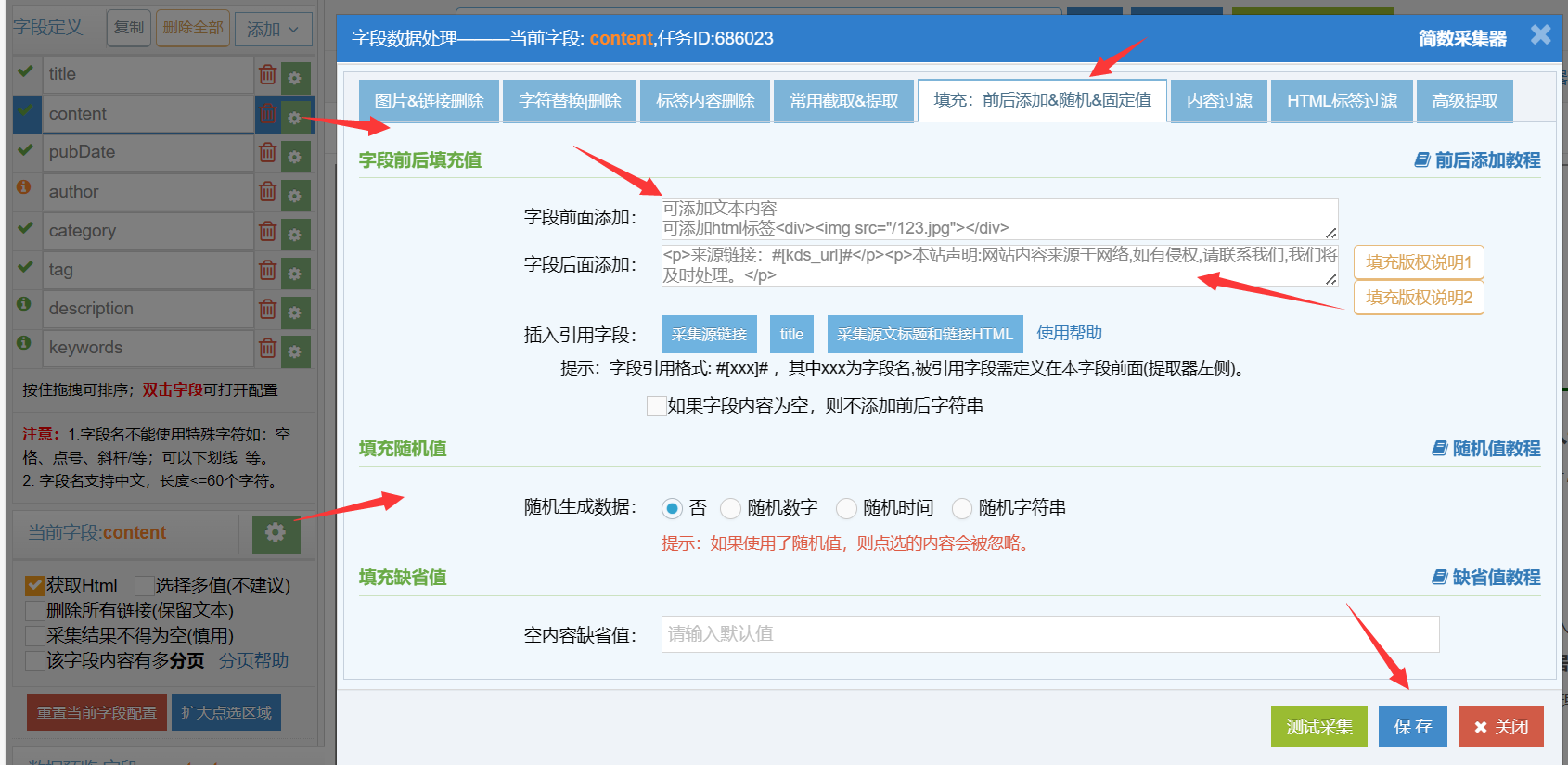
1)字段前后填充内容
可选择在字段前面或后面添加内容,内容可以是文本和html标签,系统提供两种版权说明供用户方便使用。
2)引用其他字段内容
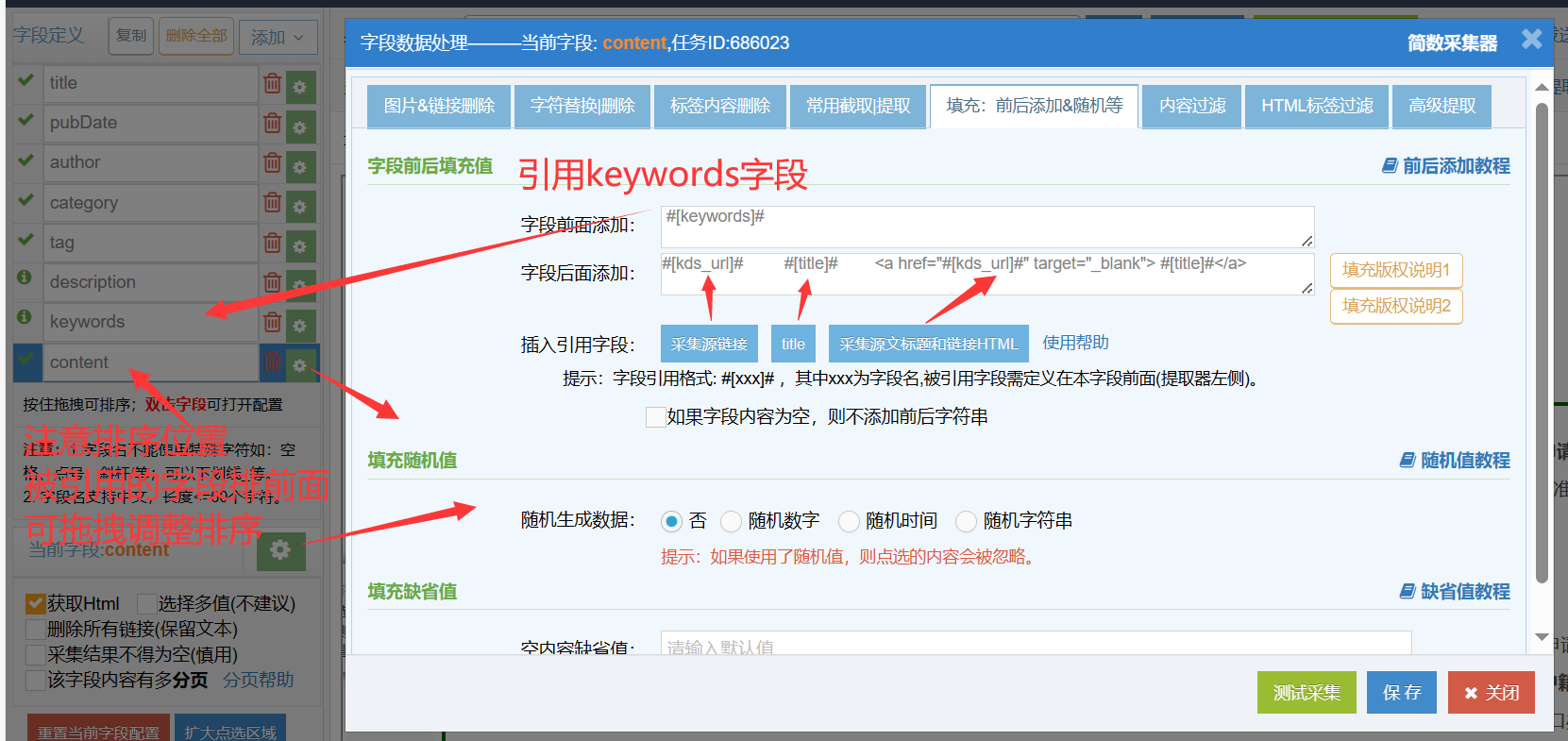
可引用同一条数据的其他字段采集内容:(示例为content字段引用keywords字段内容)
1. 被引用的字段要在当前设置字段的上面;(例图中keywords字段在设置字段content字段上面,可拖拽调整字段排序)
2. 打开当前设置字段的数据处理,在字段前面或者后面添加被引用字段,引用格式写法为:#[字段名]#;(例打开content字段的数据处理,在字段前面添加#[keywords]#)
3. 保存,测试采集验证正确性和查看效果,支持和文本、html标签等内容搭配使用;
4. 字段引用格式说明: #[xxx]#,其中xxx为字段名,例如#[title]#、#[tag]#等详情提取器已存在的字段,还有特殊字段#[kds_url]#,是指采集源的原文章链接;
提示:调整字段的位置,可以通过拖拽字段来实现。
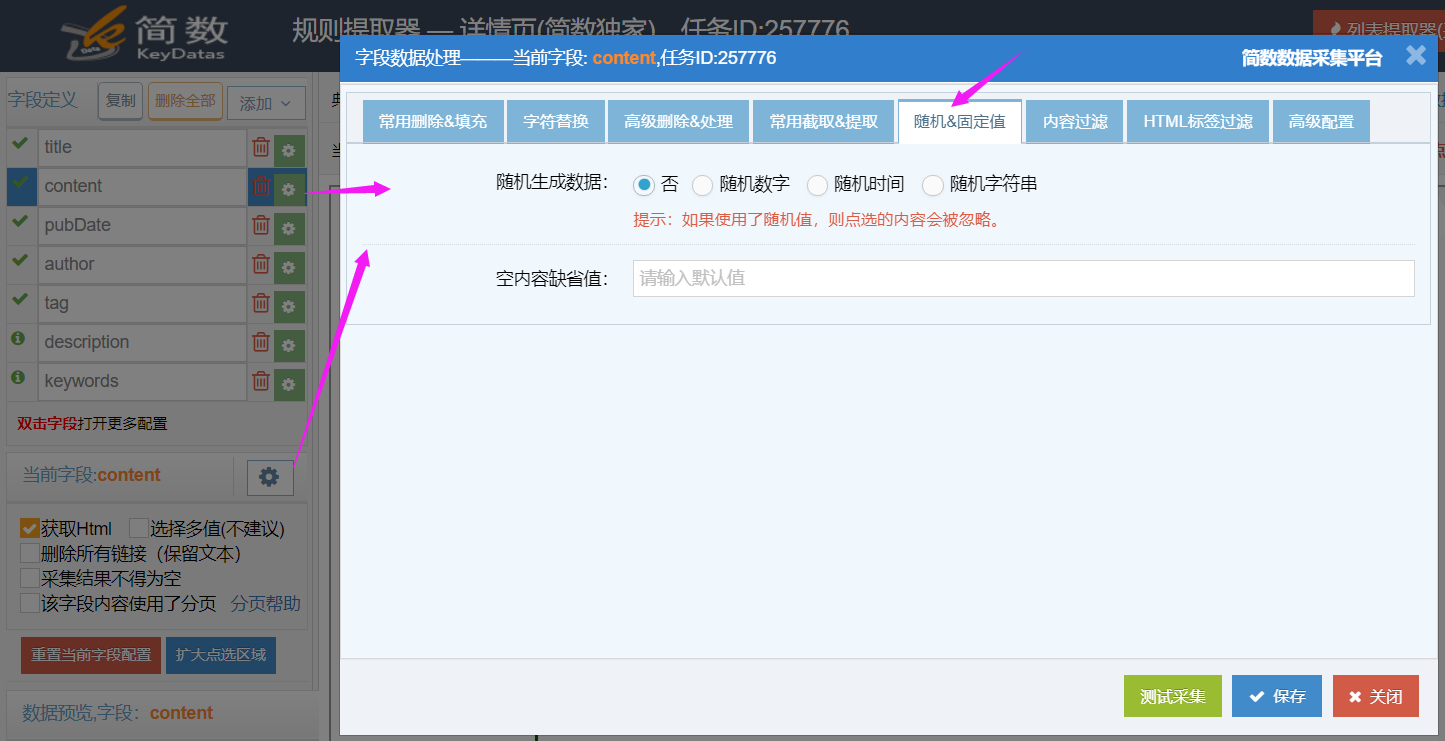
3)默认值&固定值&随机值
字段内容可以设置为默认值、固定值和随机值。
配置方法如下:
5-3-1. 字段有默认值 | 5-3-2. 字段为固定值 | 5-3-3. 字段为随机值
I. 字段有默认值
字段可以设置一个默认值,当该字段采集内容为空时,自动填充该字段【空内容缺省值】处填写的默认值。

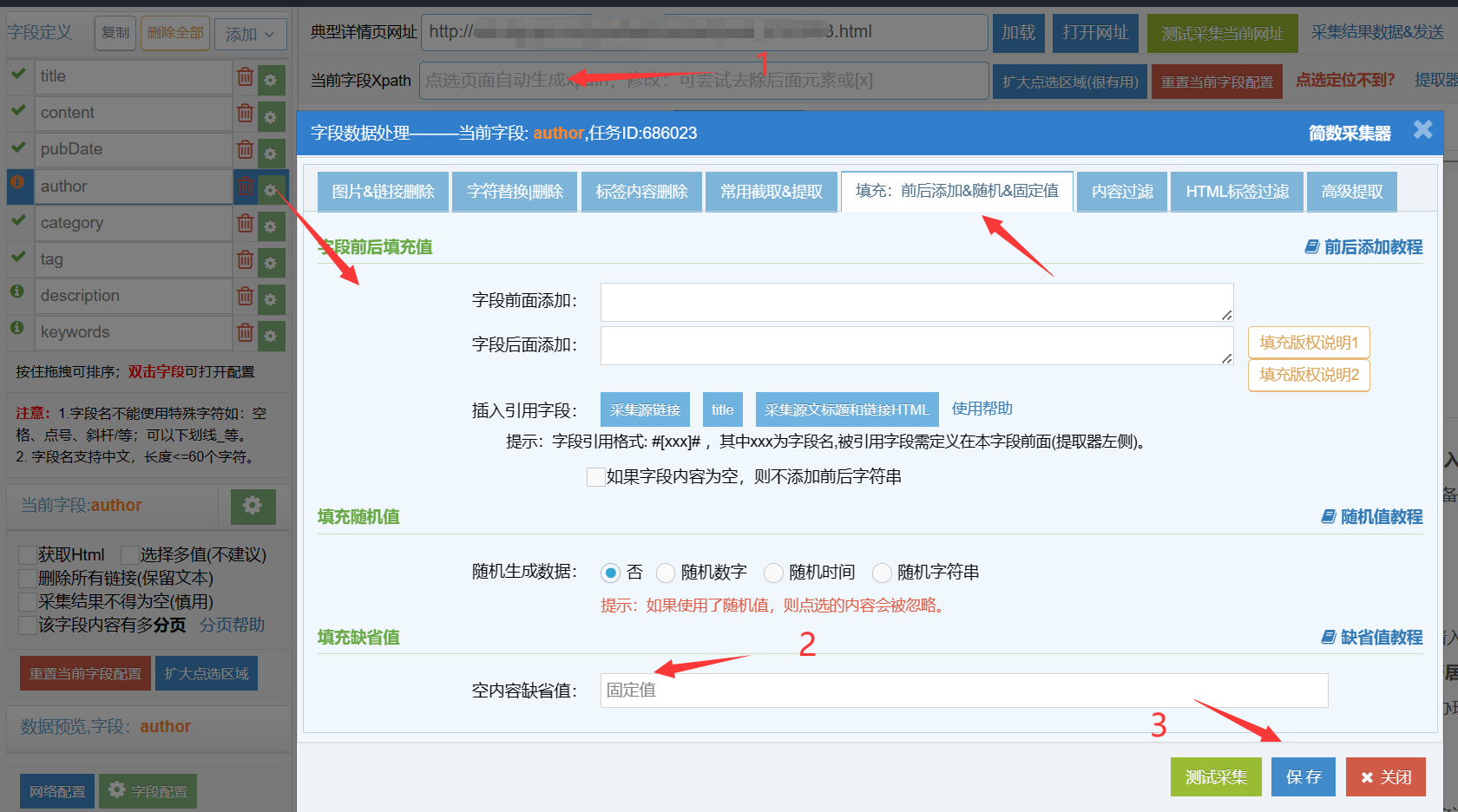
II. 字段为固定值
字段内容设置为固定值,前提是该字段不点选采集区域(当前字段xpath为空),即不采集直接为空内容,然后在【空内容缺省值】处填写固定值。
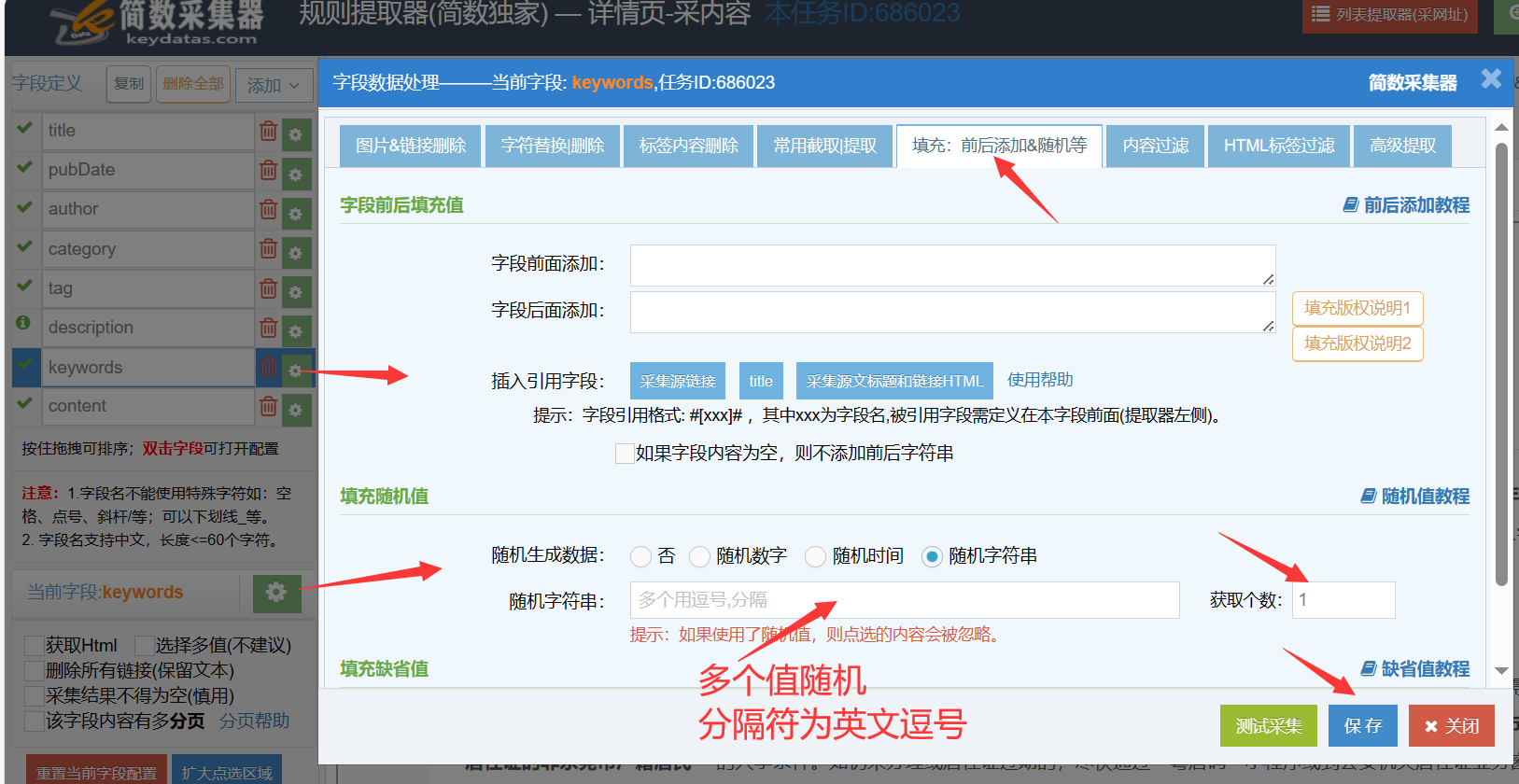
III. 字段为随机值
字段内容设置为随机值,可以设置为随机数字、随机时间、随机字符串等;
注意:使用了随机值,如果该字段有点选的采集内容会被忽略;
随机数字(需设置范围,整数);
随机时间(需设置范围,年月日);
随机字符串:可设置多个值(用英文逗号分隔),每条数据采集时都会随机抽取一个值(可设置随机获取多个),一般用作随机分类等;
6. 内容过滤排除(设置屏蔽词)
根据采集内容中包含或不包含指定字符、文本长度、图片下载失败数量等条件,判断是否过滤数据不采集入库。
内容过滤的几种方式:

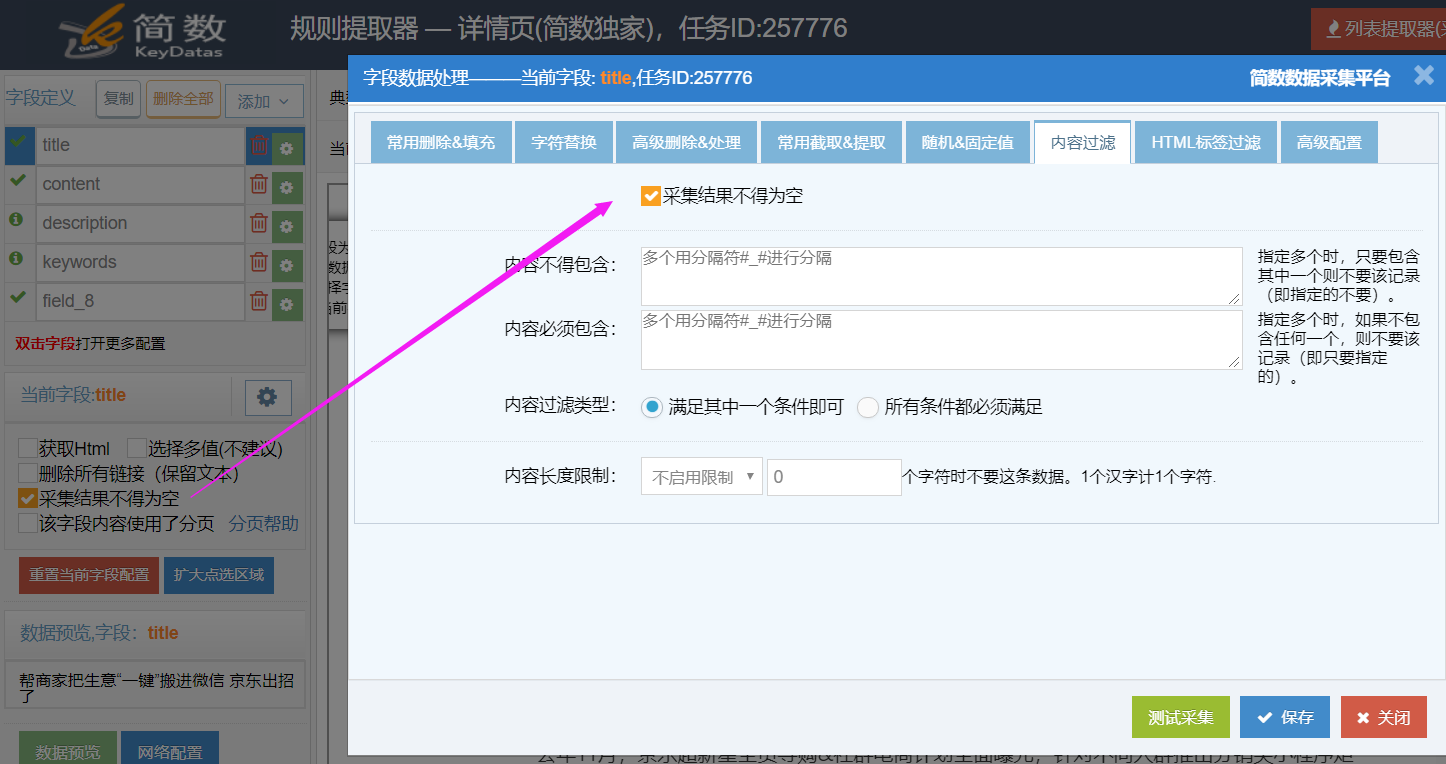
1)采集结果不得为空
作用是当该字段采集内容为空时,此数据不采集入库,title字段默认启用该功能,可过滤不同结构的广告或专题页面;
勾上是生效,一般在常见数据处理设置(相关联的,只设置一处即可),记得保存;
2)内容过滤
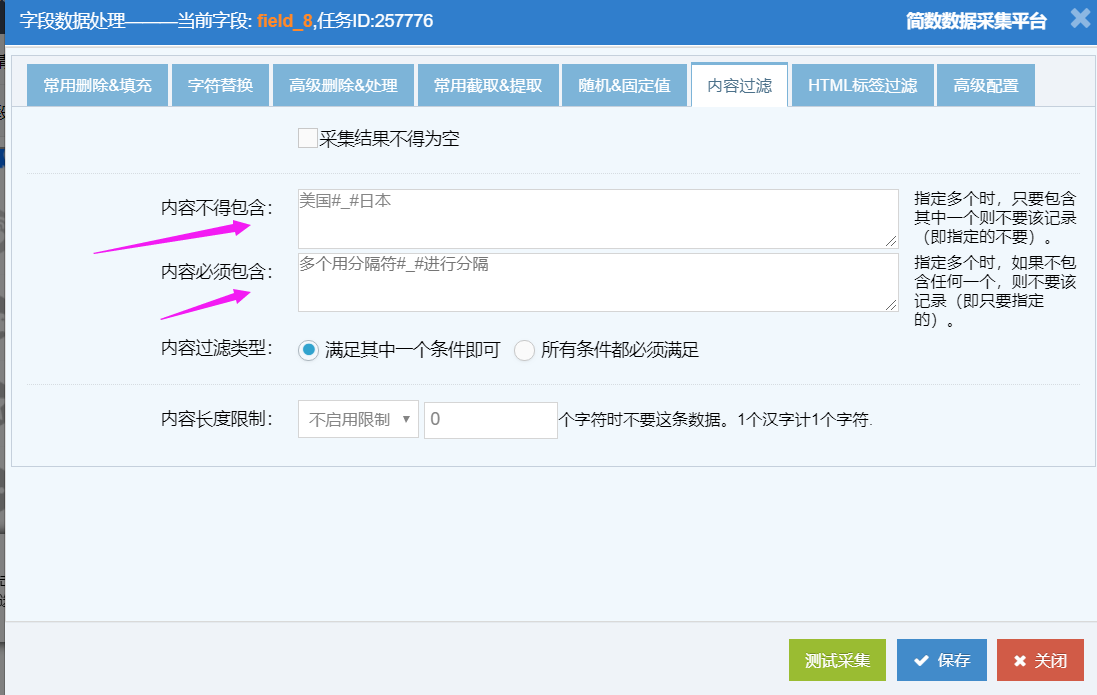
可设置当字段采集结果不得包含或必须包含某些内容(例如词语,短语等)时,数据是否采集入库;
内容不得包含:填写文本词语,如果在该字段内容中出现了,这条数据就不会采集入库了;
指定多个时用分隔符
#_#隔开(例:关键词1#_#关键词2#_#关键词3),只要包含其中一个,则不要该记录(即指定的不要)。内容必须包含:填写文本词语,如果在该字段内容中出现了,就采集入库,反之没出现则不入库;
指定多个时用分隔符
#_#隔开,如果包含其中任何一个,则要该记录(即指定的要)。内容过滤类型:
I、【内容不得包含】和【内容必须包含】只设置其中一个功能时,选择【满足其中一个条件即可】(默认); II、【内容不得包含】和【内容必须包含】同时生效,选择【所有条件都必须满足】;
注意:设置内容过滤,建议同时启用采集结果不得为空,因为字段若为空,系统不会进行内容过滤,会直接采集入库;
3)文本长度过滤
可设置当该字段采集内容文本长度小于、大于、等于或不等于X(数字)个字符时,数据不采集入库;(默认不启用)
注意:1个汉字或英文字母或数字都是计1个字符;

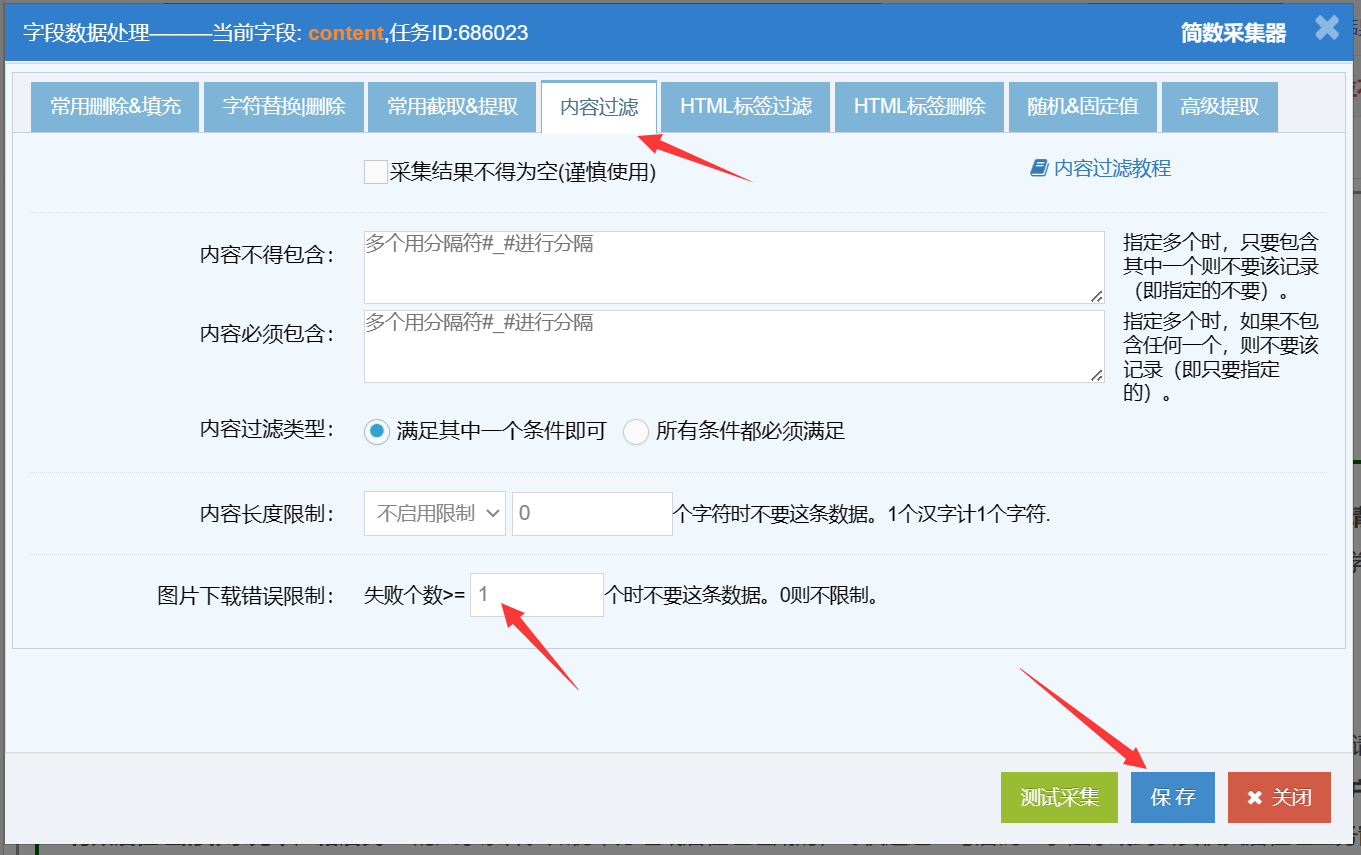
4)图片下载失败过滤
可设置某个字段采集内容中的图片下载失败超过多少个时,数据过滤不采集入库。(默认为0即不启用,通常是在content字段设置)
注意:使用图片下载失败过滤,要先设置【图片下载配置】功能。
7. HTML标签过滤
可过滤不保留指定HTML标签,如table、hr、img等。(提示:用户一般不需要配置,简数采集器已默认过滤不常用的标签);

使用说明:
1)基本功能
使用HTML标签过滤功能的前提,该字段要为获取HTML,且删除的只是HTML标签本身,标签中的文本是保留的;
系统默认使用【过滤部分html标签】功能(勾上即启用),该功能会过滤掉不常用的标签和标签属性(属性会删除class,id,alt等,保留style),如果勾掉不启用,会保留原文的全部HTML标签和属性;
保留标签属性:alt和title,这两个属性一般是出现在图片标签里,默认不启用;
2)自定义HTML标签过滤
如果要自定义选择保留HTML标签,不使用系统默认的HTML标签过滤,请按照以下操作:
I、 【过滤部分html标签】功能勾上启用;
II、 点击【重置为默认】按钮,显示系统默认的过滤HTML标签规则;
III、勾上的标签是保留的,按照自己需求选择要保留和过滤的HTML标签,最后记得保存;
下图例子是保留div标签操作:
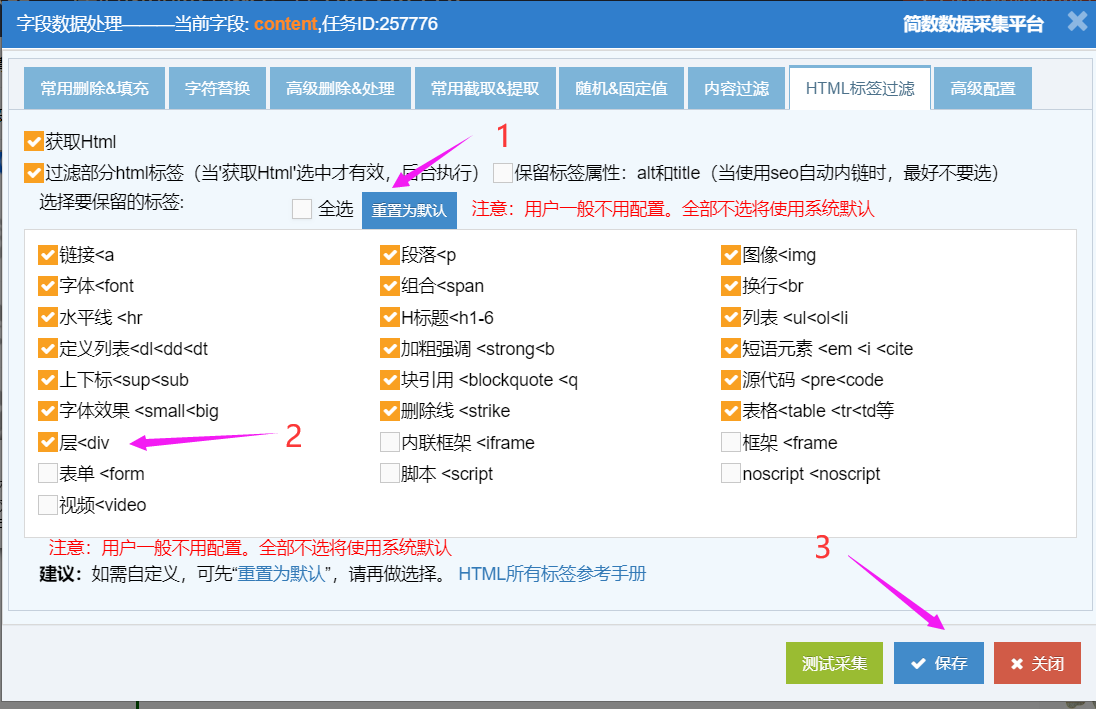
注意:如果保留的标签不存在,可以联系客服(qq:3043176563或3071166977)。
8. 高级提取
高级提取可设置采集没有显示在页面上的内容,例如获取网址,图片链接,HTML标签某个属性的值等;
具体使用说明:
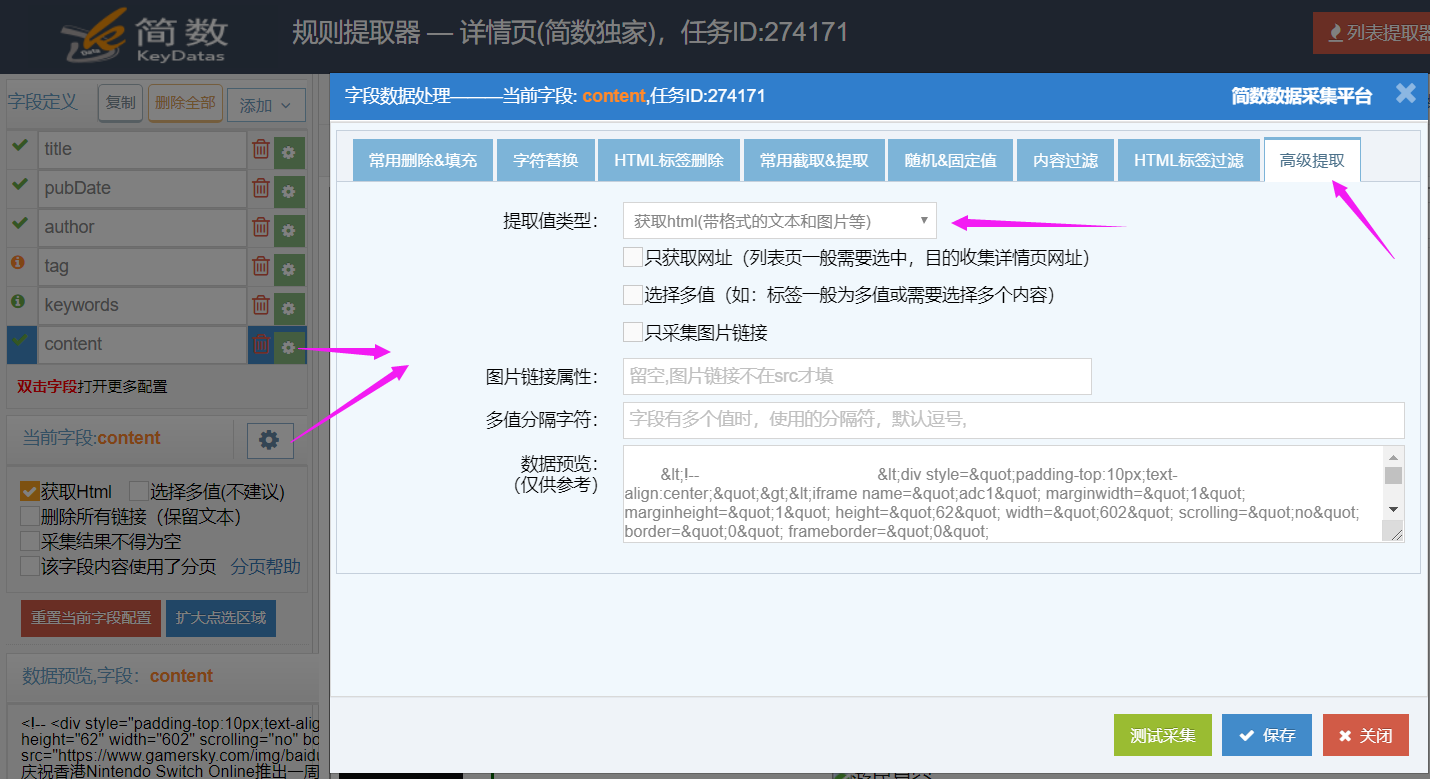
1)采集内容类型
设置不同的提取值类型,可以获取到不同类型的内容:常见的文本,含有HTML标签的内容、HTMl标签的属性等;
I、快捷获取网址或图片链接
系统提供了几个快捷功能:
只获取网址:勾上启用功能,自动设置获取a标签的链接(href属性),前提是该字段要选择a标签才能生效;
只采集图片链接:勾上启用功能,自动设置获取img标签地址(src属性),前提是该字段要选择img标签才能生效;


II、提取值类型
提取值类型可选择以下选项:
文本:纯文字内容,无任何格式;
获取html(有排版的文本和图片等):获取定位标签内的HTML标签和内容,图片和文章排版会保留,正文content字段默认使用该提取值类型;
OuterHtml:获取定位标签本身及在内的HTML标签和内容,比【获取html】多了一个HTML定位标签;
OwnText:仅获取本定位标签的文本,不含内嵌子孙标签的文本;
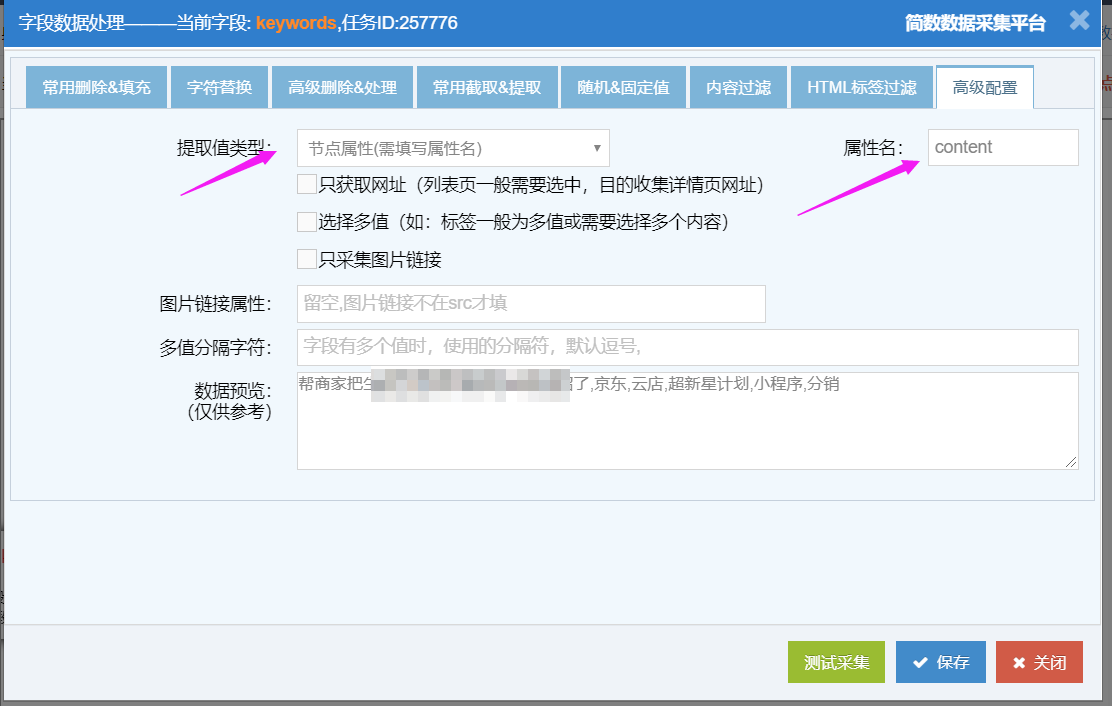
节点属性(需填写属性名):可获取定位标签中的属性值,需填写对应属性的键名称;
随机值:提示该字段为随机值,实际使用请到 【随机&固定值】选项卡中设置;
例如采集meta标签的content属性:
<meta name="keywords" content='采集的内容'/>
2)图片链接属性
系统采集图片默认从img标签的src、data-src等常见属性获取图片链接,默认留空即可;
如果采集的图片无法显示,可能是图片链接存放在其他特殊属性中,需对应填写图片链接正确所在的属性;
假设一网站的正确图片链接在origin-src属性;

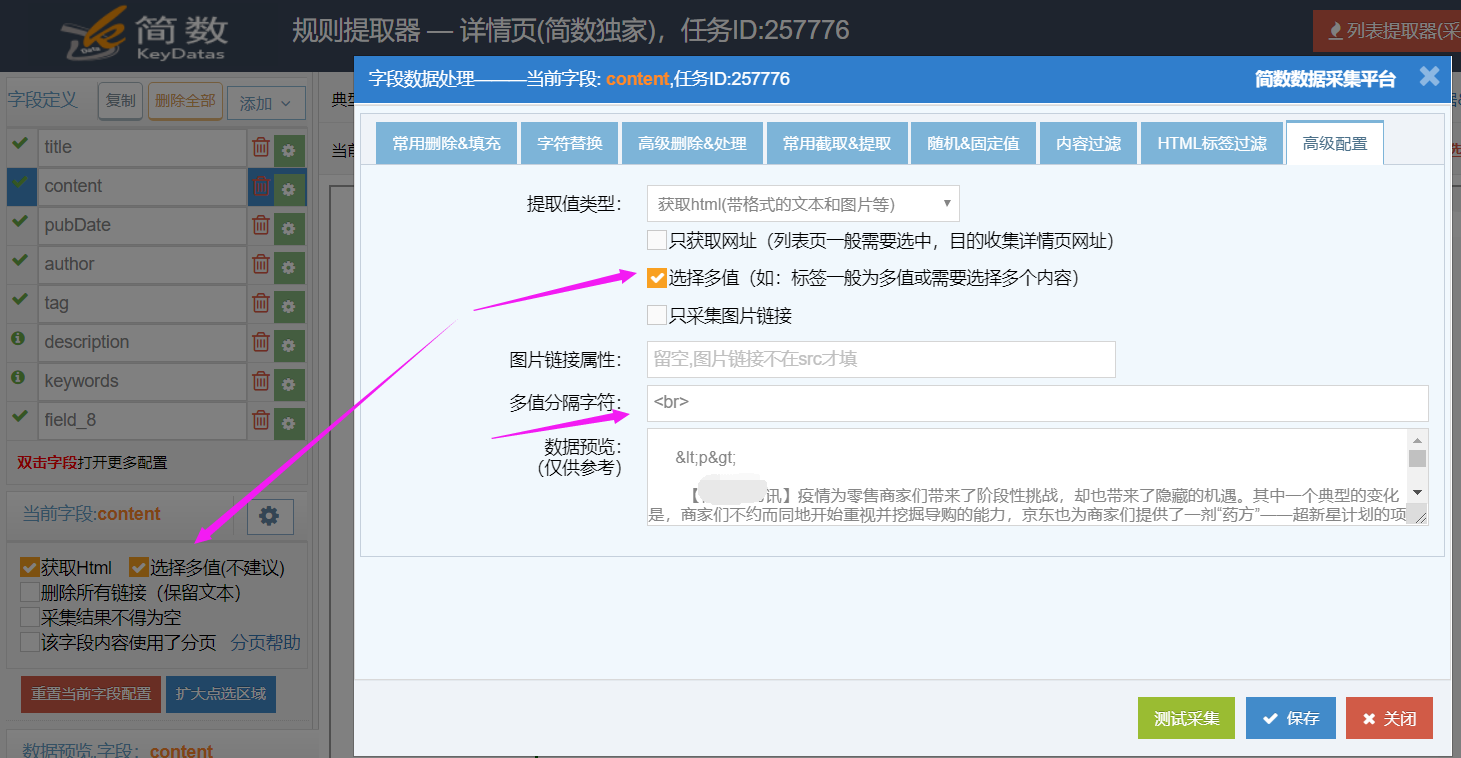
3)选择多值
I、功能简介
勾上启用功能,支持点选多个采集区域内容合并,分隔符默认是逗号,【多值分隔字符】可以修改,一般是填上换行标签<br>或者不填写为空;
注意:不建议使用选择多值,因为多值采集正文时很大可能会导致排版丢失,所以采集正文还是优先整体选择,采集标签等就可以使用选择多值功能;
II、多值操作
1)多值选择一般是在常用数据处理设置的,先勾上选择多值;

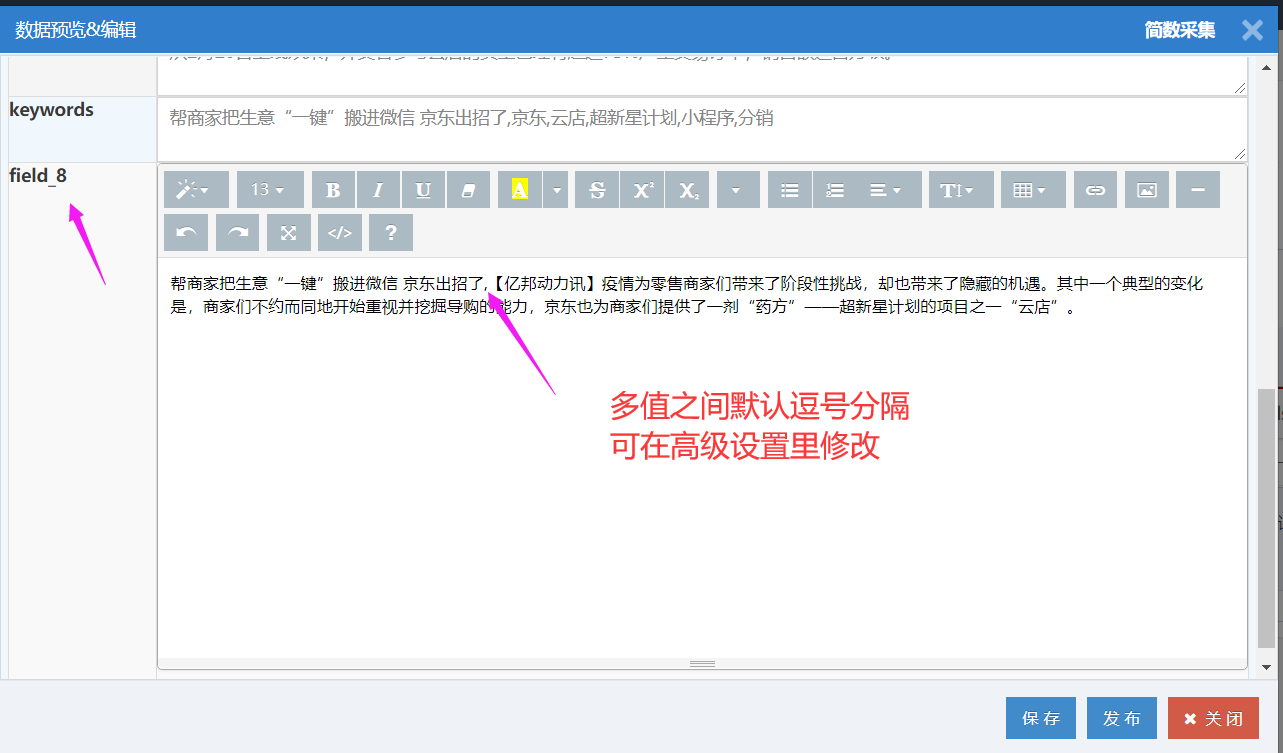
2)点选你要组合的几个采集区域,假设组合标题和第一段内容,选择后可以看到多值的特征:xpath是两个路径合并的,中间分号分隔,数据预览分成了两个,中间用横线隔开;
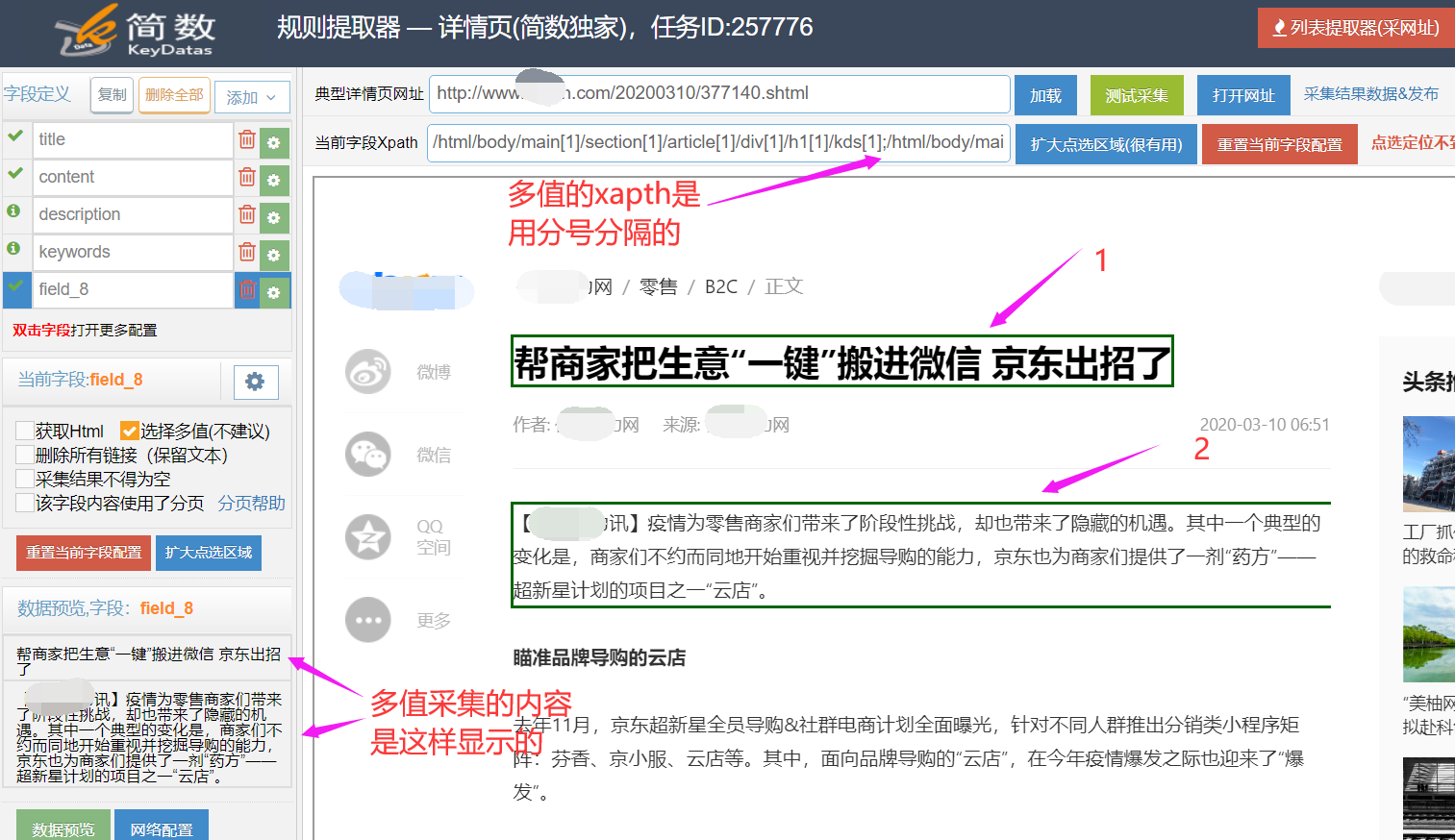
3)多值的采集结果;
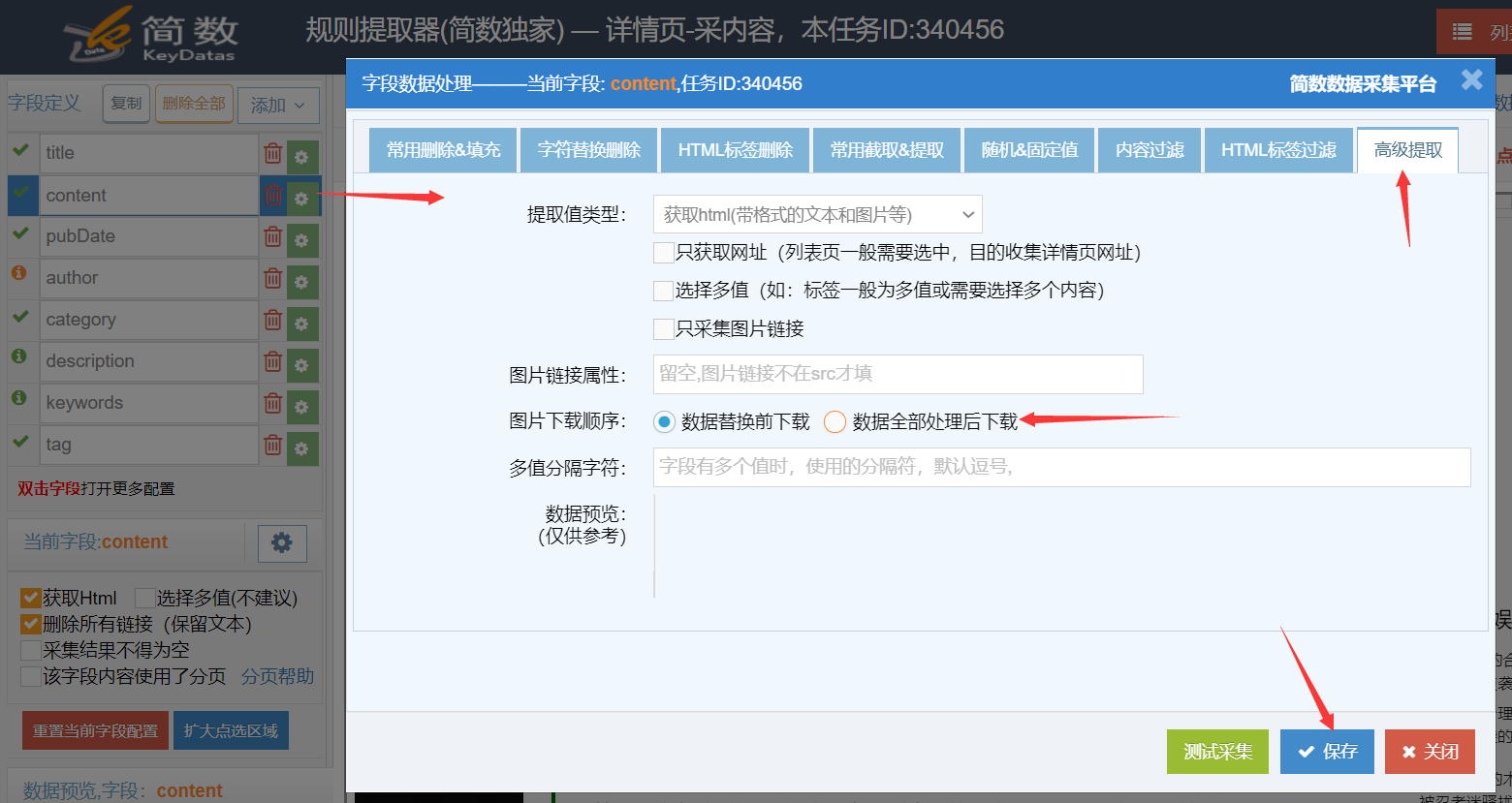
4)图片下载顺序
如果采集前设置了图片下载功能,默认是【数据替换前下载】,即先下载图片再做其他数据处理。
可以选择【数据全部处理后下载】,即先做其他数据处理最后才下载图片。
9. 已采集数据处理
已采集入库的数据如果需再补充处理,可以在任务的【结果数据&导出发送】页面,点击【数据处理工具】按钮。
已采集数据处理,一般用于补充处理。建议采集前,在详情提取器配置字段数据处理,采集时自动执行数据处理功能,无需手动执行了,更完善方便快捷。