简数导航:简数首页 简数控制台 采集入门教程 数据导出发送 采集翻译
特殊网页提取网址(如xml、txt、rss、json等)
简数采集器正则获取链接功能可以提取各种网页中的网址,包括如xml、txt、rss、json等特殊网页(根据各自的规范要求,会把多个文章网址直接罗列显示在页面里)。
如果默认采集模式下获取不到网址的列表页,也可以尝试使用正则获取链接功能提取网址,该功能基本可以获取任意页面中的网址!
1.列表页提取网址使用说明
在简数采集器控制台,打开对应采集任务的【列表提取器】,然后在【列表页网址类型】处选择【特殊网页(如xml、txt等用正则获取链接)】,系统便会切换为正则获取链接模式,自动识别并获取页面中的全部网址链接,最后记得保存。
接下来按常规流程配置详情页采集规则即可。
备注:【提取链接正则】处一般不用修改,系统默认填写获取网址链接的正则表达式。
2. 采集xml、txt、rss、json等特殊网页中的网址
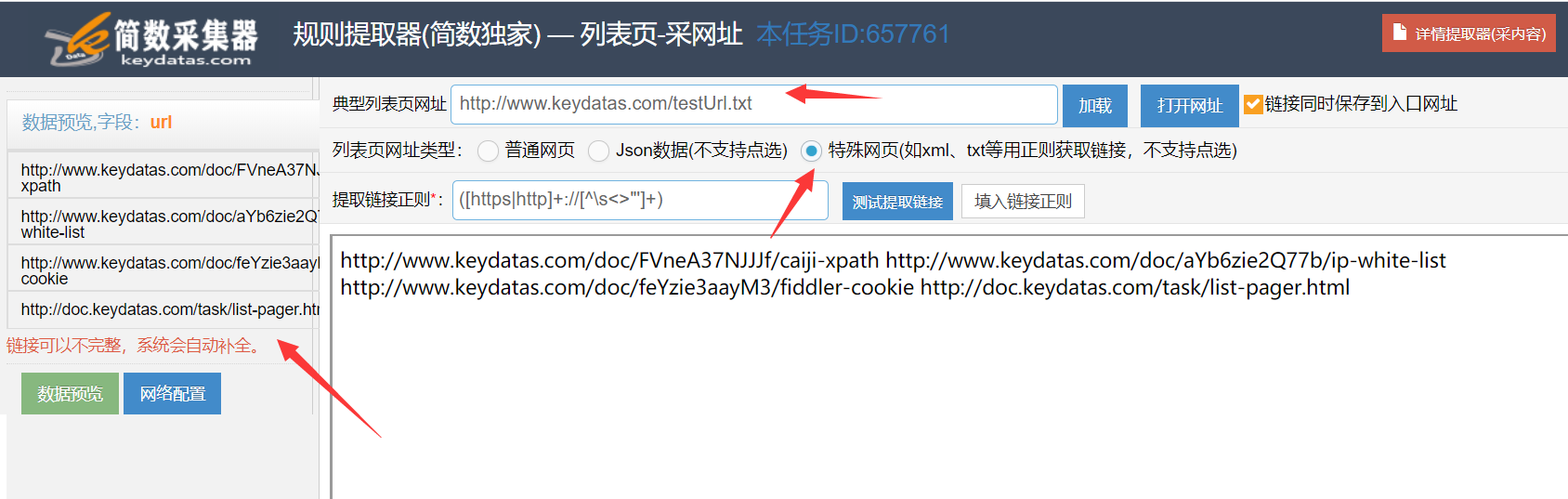
1)采集txt特殊网页
txt特殊网页里,多个文章网址一般是以换行、或空格、或分号为分隔符。
如果采集大量无规律的文章网址,可以先将这些文章网址存放到txt文件里 --》然后上传该txt文件到用户网站某个目录下 --》最后将此txt文件的访问地址作为列表页来采集。
备注:建议一个页面的网址数量不超过3万。
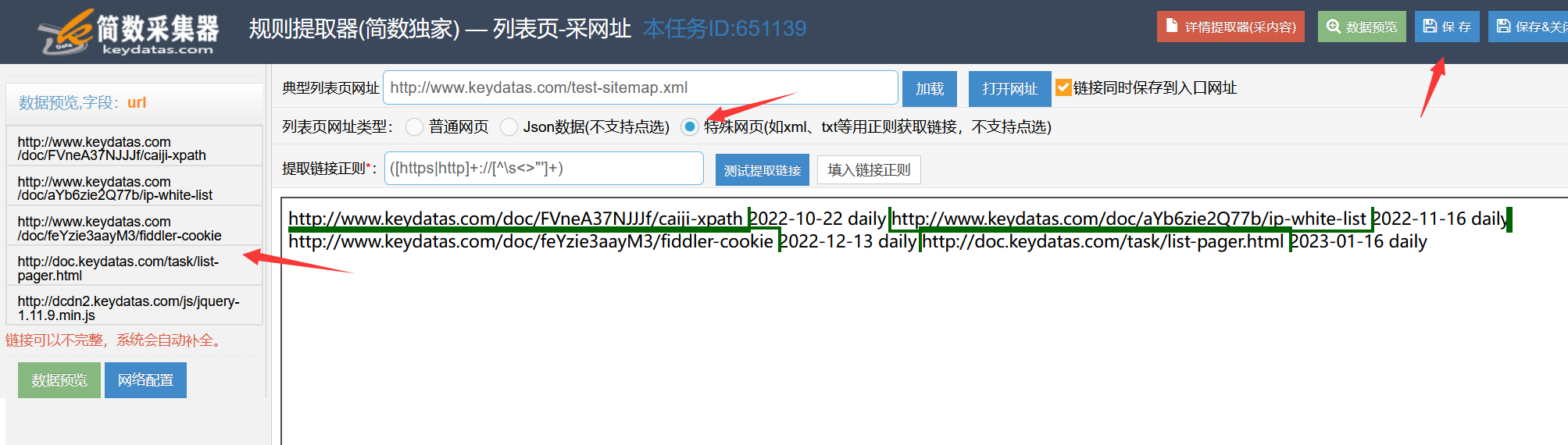
2)采集xml特殊网页
xml特殊网页,一般是网站地图(sitemap)页面,可以使用正则提取页面中的网址。
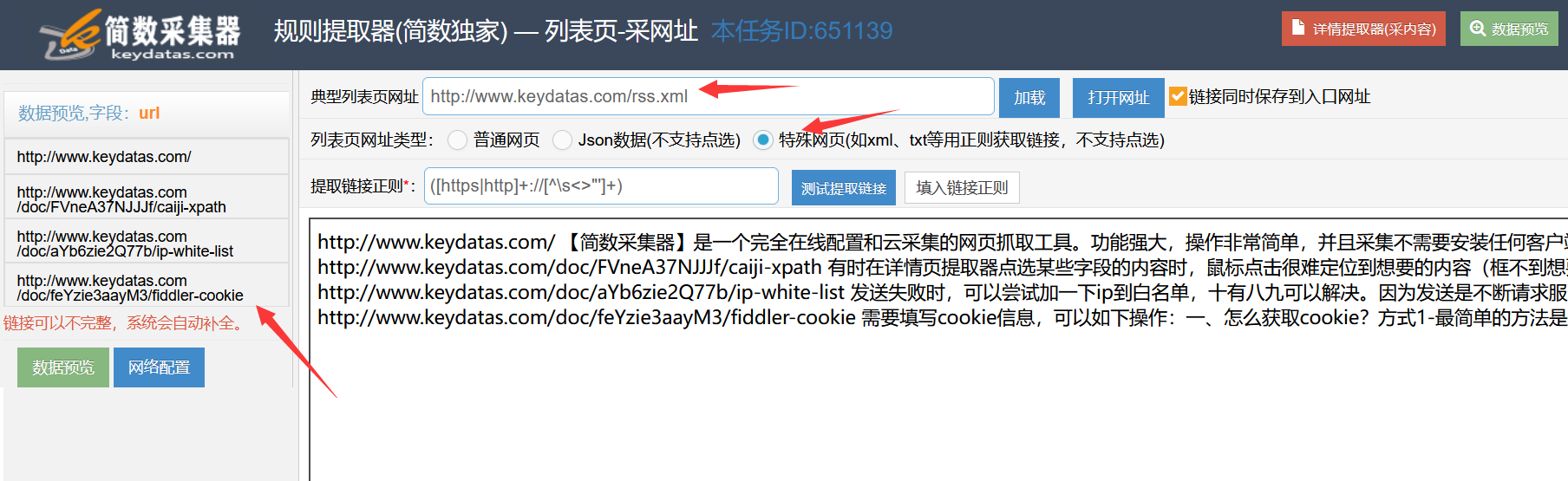
3)采集rss特殊网页
rss特殊网页,会把文章对应的网址,标题,描述等信息都显示在页面里,可以使用正则提取页面中的网址。